SpringCloud
架构的发展
单一式 -> 垂直式 -> 分布式 -> SOA流式 -> 微服务
单一式就是普通的全部功能都在一个项目中的情况
垂直式是缺少相互调用的核心的一种架构设计
分布式架构其实就是将多种不同的服务相互之间拆开,拆开后,负责不同功能的主机,某一个功能可以有多台主机共同负责
SOA流式,SOA流式对比普通的分布式架构,主要区别在于内部不同服务的主机之间进行交流是通过共同的总线来实现的,因此但是这种架构存在着对总线依赖过高的问题,当总线出现问题,那项目的可靠性就会受到巨大的影响
微服务架构,相对比于SOA流式,微服务去除了总线的概念,反而将总线换成了注册中心的一个概念,在注册中心的帮助下,不同服务的主机可以知道所需要调用服务的目标服务器的相关调用信息,然后再调用即可。
SpringCloud的常见组件介绍
- 服务网关 (OSS、ZUUL,通过OAuth2、Shiro、以及容峰限流)
- 服务注册发现 (zookeeper、nacos、eureka[不维护]、Consul)
- 配置中心 (zookeeper、apollo、携程、SpringCloud Config[不维护])
- 调用链监控 (cat、大众点评、SpringCloud Sleuth)
- Metrics监控 (kairosDB)
- 日志监控 (ELK 分布式日志信息收集 [一般会配合Kafka])
- 监控康检查和告警 (zalando ZMon)
- 伪RPC调用的负载均衡 (Ribbon原生,实际开发用feign -> 已升级为 loadbalence + openfeign)
其他常见的服务还有:Hystrix断路器、SpringCloud Bus[不维护]总线、SpringCloud Stream消息驱动、分布式请求链路追踪、SpringCloud Alibaba Sentinel熔断与限流、SpringCloud Alibaba Seata分布式事务、服务部署Docker与K8s
SpringCloud组件组成
- 注册中心 nacos
- 服务调用 openfeign (做了个负载均衡的调用)
- 服务调用 openfeign
- 服务降级 sentinel
- 配置中心 nacos / appollo
- 消息总线 nacos
dubbo和SpringCloud的区别
dubbo本身是SOA流架构之中的一种协议,他其实已经算是旧时代的一员,不能认为他可以是一个框架技术。他没有注册中心服务网关、熔断器、服务跟踪等功能dubbo什么都没有。
并且在SpringCloud Alibaba之中dubbo已经成为其中一部分的。利用了dubbo的RPC调用。
如果是为了追求快,只是想单纯的调用其他服务器的相关功能,不追求其他的类似于注册中心服务等相关功能的话,可以直接选用dubbo,而如果是想管理这个微服务集群的话,那就需要使用Spring Cloud来进行实现。
SpringCloud组件配置
注册中心配置
Zookeeper
-
下载Zookeeper,下载完毕后,修改Zookeeper的配置文件zoo_sample.cfg为zoo.cfg,并进行相应配置信息修改。如果是windows下,直接打开server.cmd即可,如果是linux暂时不知道。
-
首先需要在SpringCloud的父项目下,对pom文件进行修改,添加SpringCloud相关的一些配置信息。
<modules> <module>xxx-xxx</module> <module>xxx-xxx</module> </modules> <!--spring boot 环境 --> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.11.RELEASE</version> <relativePath/> </parent> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <!--spring cloud 版本--> <spring-cloud.version>Greenwich.RELEASE</spring-cloud.version> </properties> <!--引入Spring Cloud 依赖--> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> -
在父工程下,直接新建两个module,然后对新建module进行操作,可以将一个module配置为zookeeper目录结构下的生产者模型,另外一个则配置为zookeeper目录结构下的消费者模型。
调用方provider 先修改pom文件,然后修改yml文件
<dependencies> <!--springcloud 整合 zookeeper 组件--> <dependency> <groupId>org.springframework.cloud</groupId> <!--zk发现--> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.9</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies>然后修改provider的yml文件
server: port: 8004 spring: application: name: zookeeper-provider cloud: zookeeper: connect-string: 127.0.0.1:2181 # zk地址最后再启动类上加上关键,发现客户端的注解 (其他部分的代码和正常项目基本一致)
@EnableDiscoveryClient
消费方consumer 先修改pom文件,然后
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <!--sprin gcloud 整合 zookeeper 组件--> <dependency> <groupId>org.springframework.cloud</groupId> <!--zk发现--> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.5.6</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies>然后对yml进行配置
server: port: 8005 spring: application: name: zookeeper-consumer cloud: zookeeper: connect-string: 127.0.0.1:2181 # zk地址Consumer的配置启动类,启动类和Provider的启动类像似加上注解@EnableDiscoveryClient就好了
最后,就需要实现远程调用了,以往也可以实现远程调用,但是需要通过RestTemplate对象,对准确的url发起调用如下图所示
@Autowired private RestTemplate restTemplate; ··· ··· String url = "http://localhost:8081/goods/getGood/" + id; String goodJosn = restTemplate.getForObject(url, String.class); ··· ···但是现在,我们只需要通过使用DiscoveryClient来获取对应的实例,然后通过实例获取host和uri,即可通过这两个信息,调用restTemplate实现远程调用。
@Autowired private RestTemplate restTemplate; @Autowired private DiscoveryClient discoveryClient; List<ServiceInstance> instances = discoveryClient.getInstances("zookeeper-provider"); if (CollectionUtils.isEmpty(instances)){ System.out.println("集合为空"); } //拿到所需的uri和host等信息,通过某种策略知道是哪一个 ServiceInstance instance = instances.get(0); String host = instance.getHost(); System.out.println(JSON.toJSONString(instance)); int port = instance.getPort(); String url = "http://" + host + ":"+ port + "/goods/getGood/" + id; String information = restTemplate.getForObject(url, String.class); return new Goods();
OpenFeign 负载均衡+透明化调用
Ribben/Feign/OpenFeign (因为Ribben已经被淘汰,所以不打算学Ribben,直接上手Feign算了)
Ribben并没有实现透明化调用,在Ribben之中还是需要通过使用RestTemplate的方式来做一个getForObject的方式来实现远程调用,虽然好像已经比较简单就可以实现调用了,但是事实上还是很麻烦,想进一步处理的话,就需要进一步学习OpenFeign。
OpenFeign的使用
由于远程调用本身这一事件本身只发生在消费端,所以,在实际的开发过程之中,我们只需要去管,消费端的相关代码及其配置即可。
-
首先在消费者端加上相关依赖
<!-- 负载均衡跨服务调用 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter- openfeign</artifactId> </dependency> -
在启动类上加上注解
@EnableFeignClients //开启远程Feign的调用 -
创建Feign相关的接口类,然后将需要调用的接口方法放入相关的接口类之中
@FeignClient(value = "zookeeper-provider") public interface GoodFeign { //需要远程调用的方法 (注意url需要将restController的前缀和 后续方法的url都写上) @GetMapping("/goods/getGood/{id}") public Goods getGood(@PathVariable Integer id); } -
最后在消费者的调用之中通过使用@Autowired导入刚编写的Feign接口,调用即可
//使用Feign的方式实现远程调用 @Autowired private GoodFeign goodFeign; @GetMapping("/add/{id}") public Goods add(@PathVariable("id") Integer id) { Goods good = goodFeign.getGood(id); return good; }
OpenFeign的超时设置(基于Ribbon)
避免性能太慢了,卡了出现一个不好的使用体验(慢了、卡了直接返回错误信息)
为了解决该问题,可以通过在项目之中配置ribbon的设置
主要的配置项目
ribbon:
ConnectTimeout: 1000 #连接超时时间默认 1s
ReadTimeout: 3000 #逻辑处理的超时时间,默认1s
ConnectionTimeout:如果发生了超时操作 -> 报错信息 Connect timed out executing
ReadTimeout:如果发生业务处理操作超时 -> 报错信息 Read timed out executing
OpenFeign日志信息的打印
将详细调用的具体的信息,通过日志的方式打印出来。
实现步骤:
-
yml上的主要的配置项目
#设置当前的日志级别,debug,feign只支持记录debug级别的日志 logging; level: com.leticiafeng:debug -
建立FeignConfig实现日志的打印
(设置方法level,并且限制返回对象的范围是FULL [本质上Logger.Level是一个枚举类])
枚举的选择范围有:BASIC(只记录请求和URL、返回状态码)、FULL(全部都要打印)、HEADERS(只打印请求头和响应头的东西)、NONE(不打印)
@Configuration public class FeignLogConfig{ @Bean public Logger.Level level(){ return Logger.Level.FULL; } } -
使用FeignClient实现调用(@FeignCient(value = "调用服务中心名", configuration = FeignLogConfig.class))
根据FeignLogConfig.class内部的配置来决定,哪一些日志可以被记录
(决定打印的范围,如果是Headers则就只会打印Headers、Basic则只会打印一些简单的基本信息)
@FeignClient(value = "zookeeper-provider",configuration = FeignLogConfig.class) public interface GoodFeign { @GetMapping("/goods/getGood/{id}") public Goods getGood(@PathVariable Integer id); }
Hystrix断路器(熔断机制 - 保险丝)
**他的主要核心其实是:**能让服务的调用方,快速的知道被调用方挂掉了,不至于说用户还是傻傻的等待。
hystix是网飞的开源项目,隔离访问远程服务,第三方库,防止出现级联失败(雪崩)
雪崩:一个服务失败,导致整条链路的服务都失败的情形
主要功能
主要功能其实Hystrix就只有四个部分的功能:隔离(使得确认错误所需时间变短、线程重试变少)、降级(使得发生错误,可以直接得到错误信息,而非等着)、熔断、限流
隔离
线程池隔离
本来可以认为,一个服务要知道他是否真的是出问题了,要用整个服务架构调用者的所有的线程池中线程对他进行调用,大概可以认为是100个线程的线程池,需要调用100次才能保证他确实是挂掉了
通过使用了Hystrix之后,(原本是一个服务调用者,只会有一个线程池,但是使用了Hystrix之后,会细分原本大的那个线程池)如果想知道这个线程是否可用只需要用到服务于这个服务的线程池来进行调用即可。
信号量隔离
在需求之中,往往会出现调用时需要带上请求头信息 (例如: auth鉴权信息) ,这时候,我们再去通过使用线程复制信息,然后再去调的话,会显得很麻烦。所以这个时候,我们往往是通过直接用当前带有auth信息的线程反复调用N遍,实现反复调用重试的效果。根据原本的理论,我们也要重试线程池线程数的量,来保证服务是否可用。
针对这个问题,Hystrix将某个服务的重试次数,限制为线程池总数的内的一定细分值。因此,我们只需要重复细分值的次数即可。减少了重复的次数。
降级
降级的主要场景包括:异常、超时
当出现错误,服务响应超时的时候,可以让服务提供方返回一个报错的返回信息,告诉消费方出现了异常(这一行为又被称为降级)
服务降级
出错返回报错信息的方式,Hystrix提供出了让服务提供方返回报错信息的一个操作,使其在方法调用提供服务期间,如果出现了报错,使服务响应时间超过了Hystrix要求的相应时间之后,就返回相关的报错信息。这一机制被称为服务降级
服务降级与OpenFeign的区别
需要注意的是,服务降级实现降级机制与OpenFeign有相似的点,但是需要注意的是,服务降级是服务提供方实现的一个降级操作,而不是客户端调用的时候决定的一个错误信息处理操作。所以实际上这两者并不相同
比如:服务调用方超时报错信息是Read timed out executing GET
服务提供方超时,则可以触发服务方的服务降级方法
服务降级(服务提供方降级操作)
-
在服务提供方,引入Hystrix依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netifix-hystrix</artifactId> </dependency> -
在启动类上加上Hystrix相关注解
@EnableCircuitBreaker注解使得Hystrix得到使用
-
在Controller之中定义一个降级方法,并且规定降级方法实际内容
在认为需要使用降级方法的Controller的相关接口方法上,加上@HystrixCommand方法并且标注相关的配置信息(如果要指定超时时间等,则需要在@HystrixCommand的commandProperties属性上再用上@HystrixProperty注解)
/** 降级方法(用来返回一个告知调用端发生错误信息的对象) */ /** * 根据方法定义其相关的降级方法,提供相关的降级服务 * 要求: 1.方法的返回值要和原来的方法保持一致 * 2. 方法参数要和原方法一致 * @param id * @return */ public Goods getGood_fallback(Integer id){ Goods goods = new Goods(); goods.setId(-1); goods.setTitle("provider提供方降级"); goods.setPrice(114.514); goods.setCount(114514); return goods; } /** 被调用的真实接口 */ @GetMapping("/getGood/{id}") @HystrixCommand(fallbackMethod = "getGood_fallback" , commandProperties = { //设置Hystrix的超时时间,默认为1s @HystrixProperty(name = "execution.isolation.thread.timeoutInMillseconds", value = "3000") }) public Goods getGood(@PathVariable Integer id){ System.out.println("lmffffffffff"); //模拟业务逻辑比较繁忙 try { System.out.println("好困,睡一下,大概就5s"); Thread.sleep(5000); System.out.println("醒了,但还是好困"); } catch (InterruptedException e) { e.printStackTrace(); } return new Goods(114514,"野兽森洋",114.514,114); }
服务调用方(消费方降级操作)
为了避免出现,服务提供方存在的致命错误,无法返回相关的错误信息的对象的情况出现,就需要通过使用消费端降级的方式来获得错误信息。
-
引入Hystrix依赖,在已经有了OpenFeign接口来实现对远程的服务进行调用的基础上,可以添加一个类,对OpenFeign接口进行一个实现,并且大概取名为xxxClientFallback,并且使用@Component注解进行过配置,实现OpenFeign的相关调用方法
@Component public class GoodFeignClientFallBack implements GoodFeign { @Override public Goods getGood(Integer id) { Goods goods = new Goods(); goods.setId(2); goods.setTitle("调用方实现降级"); goods.setPrice(114.514); goods.setCount(114514); return goods; } } -
在实现远程调用的OpenFeign接口的@FeginClient注解上加上新注解属性callback配置信息,即可实现调用方的服务降级。
@FeignClient(value = "zookeeper-provider",configuration = FeignLogConfig.class,fallback = com.leticiafeng.call.GoodFeignClientFallBack.class) public interface GoodFeign { @GetMapping("/goods/getGood/{id}") public Goods getGood(@PathVariable Integer id); } -
在调用者的yml之中添加相关配置信息
# 开启feign对hystrix的支持 feign: hystrix: enabled: true即可实现相关配置。
熔断
概念:熔断机制,熔断机制的出现,是为了避免在服务器发生的大量错误导致服务器无法提供相关服务的基础上,做出来的Hystrix的相关机制。大致可以把流程认为是以下的步骤,首先在某些场景下服务器可能会出现大量的失败的情况,在失败达到一定的阈值之后,就会打开熔断机制,经过一定时间的关闭之后,服务器可以在运维的处理上,重新打开,但是这个时候熔断机制并不是完全的关闭,服务器仍然处于在熔断机制的保护之下,如果继续出现大量的失败,那就回再次进入熔断状态,而如果不再出现错误了,就重新关闭熔断机制,让服务器继续正常工作。
实际上,可以认为就是当一个外部接口,不停的发生大量的错误信息后,服务器会直接将这个接口进行关闭。在实际的模仿之中,可以将接口传入的参数进行判断,当时某个值的时候故意sleep去触发一个较长时间的资源损耗直到这个损耗的时间超过了降级所需的超时时间。这个时候,我们再换一个不受限制的值去触发接口,会发现,不被限制的值触发接口的结果也是得到了降级。
熔断机制甚至都不需要我们自己搞,或者是过多的配置,其实Hystrix本身就已经将熔断机制在自身的代码之中进行了实现。
熔断配置
当然如果想要更加细致的配置,也可以在方法提供者(provider)之中,可以在该方法的**@HystrixCommand注解的commandProperties属性配置**上加上更多的配置信息来实现相关的操作。
circuitBreaker.sleepWindowInMilliseconds:监控时间
circuitBreaker.requestVolumeThreshold:失败次数
circuitBreaker.errorThresholdPercentage:失败率
在提供者的Controller之中
@HystrixCommand(fallbackMethod = "findOne_fallback",commandProperties = {
//设置Hystrix的超时时间,默认1s
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value = "3000"),
//监控时间 默认5000 毫秒
@HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value = "5000"),
//失败次数。默认20次
@HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value = "20"),
//失败率 默认50%
@HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value = "50")
})
熔断监控
以图形化界面的方式来为运维人员提供相关的项目运行信息,Hystrix提供了Hystrix-dashboard功能,用于实时的监控微服务的运行状态。但是Hystrix-dashboard只能去监控一个微服务。除此以外,网飞还提供了Turbine,进行聚合监控。
熔断监控功能,就类似于dubbo的控制中心和监控中心一样(dubbo-monitor)一样,都是需要通过新模块或者是下载的方式来进行实现。
(本想着去试试,搞一个看看咋样,但是事实证明,我用的SpringBoot版本用不了这个鬼东西,一直显示依赖冲突,直接开摆,反正后面也不是用这个玩监控)
稍微查了一下,反正大概可以知道是spring-boot-starter-actuator和其他东西有冲突关系导致的结果。
限流
Hystrix有限流的功能,但是一般没有人会用Hystrix来做限流的实现,一般都是通过使用Nginx或者是GateWay网关之中实现。
ZUUL路由网关
路由网关的核心开发人员跑路了,后续因为没有人员进行版本迭代的开发,很快就被淘汰掉了
Spring开发人员直接接手,搞出了个GateWay作为新的一代网关
GateWay路由网关
(作为一个独立的模块而存在)
网关的功能
总的来说网关其实就是两个功能: 1. 路由、 2.过滤 (过滤一般通过使用过滤器的方式实现:)
路由
通过yml的配置即可实现。主要实现的功能有 实现动态代理、不同服务器的一个转发
过滤
通过配置过滤器的方式进行实现,而过滤器又包含有:
内置过滤器 (Gateway内部提供的过滤器)
自定义过滤器 (自己定义的过滤器)
局部过滤器 (作用于局部的过滤器)
全局过滤器 (作用于全局的过滤器)
过滤方式
目前Gateway主要支持两种内置的过滤模式: “pre"和"post"。
对于"pre"过滤器,在转发之前进行执行,可以做参数校验、权限校验、流量监控、日志输出、协议转换等工作。
(请求达到服务器之间,可以实现对请求进行处理的相关操作)
对于"post"过滤器,可以做响应之前执行,做响应内容、响应头的修改、日志的输出、流量监控等。
(请求达到服务器,服务器处理完毕后,可以实现给请求方响应之前进行处理的相关操作)
内置过滤器
- GatewayFilter:局部过滤器,针对单个路由
- GlobalFilter:全局过滤器,针对所有路由
背景
在当前的互联网大数量的背景下,不使用路由的情况下,无法解决一下的问题
而当我们引用了Gateway之后情况便会有所改变 (凸显了一个思维,没有什么东西是不能通过加一层中间层的方式来解决的,如果有,那就加两层)
客户端需要记录不同微服务地址,增加客户端的复杂性
(因为不同服务可能在不同的服务器上)
**GateWay网关的处理方式:**通过记录后缀相关的信息,来知道应该转发到哪一边的服务器上。
每个后台微服务都需要进行认证
(token认证)
**GateWay网关的处理方式:**因为他是通过抽取多一层的方式来实现的反向代理,也可以说是流量处理,所以在请求到达服务之前,我们可以利用GateWay来实现请求信息的一个鉴权
http发送请求的时候,涉及到跨域的问题
(不同服务器之间还要考虑跨域)
后台新增微服务,不能动态的知道地址的问题
(按照原来的思路,这个服务的请求甚至需要写死在前端),这个是是注册中心实现的
面对以上的问题,GateWay以添加中间层的方式来进行处理,及所有的请求在到达服务器之间都需要经过GateWay服务器,才能达到服务器。也因此,我们可以基于这个关系,利用GateWay实现请求的一个转发、鉴权、跨域等功能的实现。(在功能上类似于AOP,外层包裹然后增强)
而如果后续使用了网关,就可以1. 以一种简单但是却有效的统一的API路由管理方式;2. 在微服务之中,不同的服务器可以有不同的网络地址,各个微服务之间可以通过互相调用的方式来完成客户请求,客户端可能通过调用N个接口来完成一个用户请求; 3. 网关就是系统的入口,封装了应用程序的内部结构,为客户端提供统一的服务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、缓存、负载均衡、流量管控、路由转发等 4.在目前的网关解决方案里,有Nginx+ Lua、Netflix Zuul/zuul2 、Spring Cloud Gateway等等。
可以认为就是nginx外加一些辅助功能上的一个东西
快速入门配置
基础配置 + 路由配置
-
搭建网关的相关模块: api-gateway-server
-
引入相关依赖: starter-gateway
<dependencies> <!--引入gateway 网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--springcloud 整合 zookeeper 组件--> <dependency> <groupId>org.springframework.cloud</groupId> <!--zk发现--> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.7.1</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> </dependencies> -
编写相关的启动类(ApiGatewayApp)
package com.ydlclass.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication @EnableEurekaClient public class ApiGatewayApp { public static void main(String[] args) { SpringApplication.run(ApiGatewayApp.class,args); } } -
编写配置文件
server: port: 80 spring: application: name: api-gateway-server cloud: # zookeeper配置 zookeeper: connect-string: 127.0.0.1:2181 # zk地址 # 网关配置 gateway: # 路由配置:转发规则 routes: #集合。 # id: 唯一标识。默认是一个UUID # uri: 转发路径 # predicates: 条件,用于请求网关路径的匹配规则 # filters:配置局部过滤器的 - id: zookeepr-provider # 静态路由 uri: http://localhost:8004/ # 动态路由 # uri: lb://GATEWAY-PROVIDER predicates: - Path=/goods/** filters: - AddRequestParameter=username,zhangsan - id: zookeeper-consumer uri: http://localhost:8005 # uri: lb://GATEWAY-CONSUMER predicates: - Path=/order/** # 微服务名称配置 discovery: locator: enabled: true # 设置为true 请求路径前可以添加微服务名称 lower-case-service-id: true # 允许为小写
过滤器配置
首先,Gateway提供了大量的内置的过滤器,我们的一些较为普通的需求可以直接在过滤上进行配合来实现。
由于SpringCloud GateWay的内置过滤器实在太多,这里直接放到另外一种文档之中进行介绍。
[Gateway内置过滤器,详细介绍文档](./SpringCloud Gateway内置过滤器.md)
需要注意的是,每一个过滤器工厂都对应着一个实现类,并且这些类的名称必须要以 GatewayFilterFactory 作为结尾,这个是Spring Cloud Gateway的一个约定。例如:AddRequestHeader 对应的实现类则为 AddRequestHeaderGatewayFilterFactory。
过滤器可以分为内置局部(一个或者几个的过滤器)、内置全局(当全部都需要配置过滤器的时候)、自定义局部(很少用,很麻烦 一个或者几个特殊需求的过滤器)、自定义全局(如果要自定义,最常用的,其实是这个当全部特殊需求的过滤器)
自定义局限过滤器
为什么说自定义局限过滤器很麻烦?因为自定义内部类之中,主要为了实现具体的功能的时候首先需要将类名称为xxxPrefixGatewayFilterFactory,然后继承AbastractGatewayFilterFactory<xxxPrefixGatewayFilterFactory.Config>,在该类实现之中还要添加一个内部类借以实现继承类AbatractGatewayFactory中的xxxPrefixGatewayFilterFactory.Config,并在该类之中的apply方法之中实现过滤器的具体功能。
自定义全局过滤器
自定义全局过滤器需求背景:
在实际开发之中
- 该技术主要用于pdd,taobao,百亿补贴薅羊毛。 ip是taobao员工的,直接把他ban了
- 某些请求路径,如“goods/findByid",危险操作,用日志的方式进行记录
按照需求的实际意思,可以认为可以直接先把IP过滤器放在前面,然后再把URL过滤器放在后面
实际配置步骤:
- 在Spring-Cloud项目之中,首先建立一个用于GateWay的模块,建立相关的pom文件、启动类、yaml文件配置信息;如果已经存在,则直接建立filter文件夹,并且在文件夹下建立相关的类 (例如在filter文件夹下,建立用于拦截IP的IpFilter类)
- 建立的IpFilter类之中,需要实现相关的接口 GlobalFilter、Ordered,然后实现相关的方法,GlobalFilter对应filter (写业务逻辑)、Ordered对应getOrder方法 (返回数值,越小越先执行)
# 内置局部过滤器
filters:
- AddResponseHeader=yld.itlis # 给某个zookeeper服务添加返回体信息
# 内置全局过滤器
default-filters:
- AddResponseHeader=yld.itlils # 给全部的返回体添加的头部信息
# 自定义局部过滤器
一般很少用,为了节省时间,这里不再过多介绍了
自定义全局过滤器
# 自定义全局过滤器
@Component //添加Spring容器注解使其可以被注入Spring IOC容器
public class IpFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
InetSocketAddress remoteAddress = request.getRemoteAddress();
String hostName = remoteAddress.getHostName(); //主机名
InetAddress address = remoteAddress.getAddress();
String hostAddress = address.getHostAddress();
System.out.println(hostAddress); //IP地址
String hostName1 = address.getHostName();
System.out.println(hostName1); //主机名
if (hostName.equals("1.1.1.1")){
//当认为IP是黑客,或者是恶意访问者的时候直接拒绝请求
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
//如果不是恶意访问者,走完了,该到下一个过滤器了
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}
//URL拦截器
@Component //添加Spring容器注解使其可以被注入Spring IOC容器
public class URLFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
InetSocketAddress remoteAddress = request.getRemoteAddress();
URI uri = request.getURI();
String path = uri.getPath();
if (path.contains("goods\\delete")){
//当认为IP是黑客,或者是恶意访问者的时候直接拒绝请求
//可以通过logger的方式输出来
System.out.println("危险操作");
}
//如果不是恶意访问者,走完了,该到下一个过滤器了
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 1;
}
}
Config配置中心
Config后面开始到Sleuth的SpringCloud组件内容,属于是超大型互联网公司才可能会使用到的组件内容,在大部分的情况下,这些组件应该都是接触不到的。国内BATJ Baidu Alibaba Tencent JD,或者国外FLAG fackbook linkedin amazon google,才会有到这些非常夸张的组件。
Config为什么要存在?
SpringCloud Config的存在,其实他的定位本质上对应着Zookeeper学习时所记录的配置中心的作用基本类似,他的存在可以让我们集中管理配置文件,并且在不同的环境下不同的配置,动态化的配置更新,配置信息改变时,不需要重启就可以更新配置信息到服务。
其实总的来说,就是为了让服务器机房中的服务器,能够找到属于自己的那一份配置文件,就像是java中springBoot项目要找属于他的yml文件一样。
Config的具体工作流程介绍图
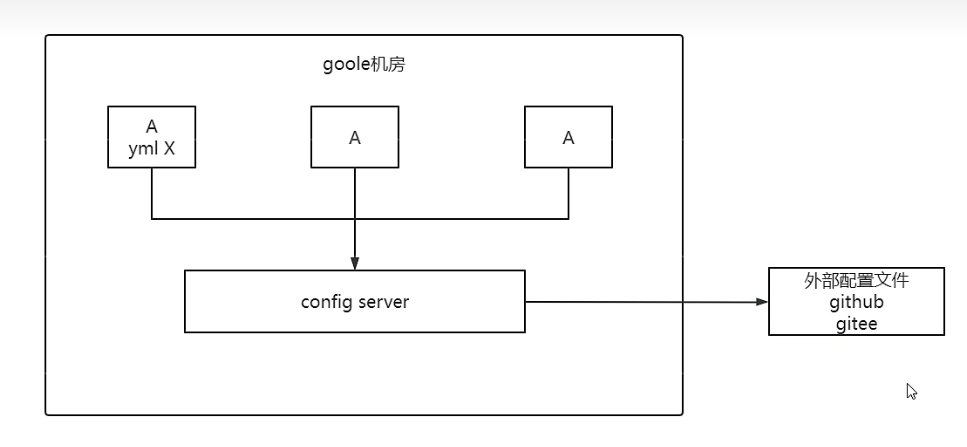
基本理解:如果要实现配置中心的相关功能,对于配置文件提供中心来说,需要单独抽取出来作为一个子模块作为微服务之中的服务配置文件集中分发点。
Config快速入门
config-server
首先配置文件提供一个配置中心需要创建一个用于存放相关信息子模块,该子模块的主要作用就单纯只是连接相关的配置文件
具体的相关配置如下:
该子模块的pom.xml文件如下:
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<!-- config-server -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
</dependencies>
该子模块的yml文件如下:
server:
port: 9527
spring:
application:
name: config-server
# spring cloud config
cloud:
config:
server:
# git 的 远程仓库地址
git:
uri: https://gitee.com/Leticia_feng/spring-cloud-config-setting.git
label: master # 分支配置
该子模块的启动类如下:
@SpringBootApplication
@EnableConfigServer // 启用 config server功能
// 开启配置中心的服务端
public class ConfigServerApp {
public static void main(String[] args) {
SpringApplication.run(ConfigServerApp.class,args);
}
}
到目前为止该项目即可通过地址 + 端口号 + git地址 + 文件路径信息查看到相关的配置文件信息
例如: http://localhost:9527/master/provider-dev.yml
config-client
首先配置获取,不需要专门的创建一个子模块来作为一个配置获取的模块,在学习代码之前,需要考虑好他的本质,获取配置中心的配置的主要作用在于用于各种模块服务,为模块服务提供相关的配置信息。因此本质上客户端这边可以将相关的代码嵌入到具体服务的相关模块之中,比如:在提供相关服务接口的一些项目子模块之中添加该内容。具体类似该部分的还有Zookeeper的provider和consumer、OpenFeign的远程调用。
具体的相关配置如下:
首先需要在子模块的相关pom文件之中添加相关的配置信息如下:
<!--config client -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
在需要从config配置中心获取配置文件子模块yml文件之中添加相关配置信息:
注意这里的配置文件名字必须为 bootstrap.yml / bootstrap.properties 否则就不起作用 (如果写的是application则会被后续覆盖,所以导致不行)
# 配置config-server地址
# 配置获得配置文件的名称等信息
spring:
cloud:
config:
# 配置config-server地址
uri: http://localhost:9527
# 配置获得配置文件的名称等信息
name: provider # 文件名
profile: dev # profile指定, config-dev.yml
label: master # 分支
在需要使用配置中心中的相关配置信息的地方添加相关的代码即可 (当然如果是直接在配置文件中有即可的地方,那就可以不管,直接用就好了)
@Value("${author}")
private String author;
@GetMapping("/author")
public String getAuthor(){
return author;
}
配置信息实时更新
当我们使用了SpringCloud Config对配置文件进行配置的时候,自然我们不用管配置文件了,但是这样并不能面对当我们在使用的时候,改变了Config配置文件的内容Config Client并不能及时的更新相关的信息。如果要实现对配置文件的及时更新那就需要进行以下的配置。
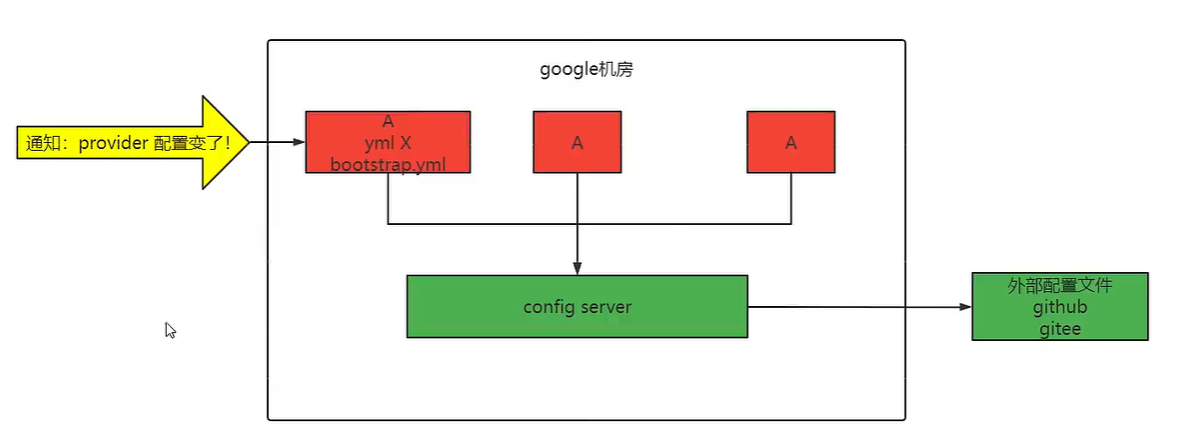
因为在学习熔断机制的时候,我们曾经学习过一个健康观测机制,actuator作为健康观测的机制来实现具体的接口健康情况的观测(虽然最终因为各种各样的原因并未跟着做出来了效果便是了)
具体详细配置
-
在config Client之中引入相关的actuator依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> -
获取配置信息类(不是启动类,要注意)font>上,添加@RefreshScope注解
@RestController @RefreshScope @RequestMapping("/information") public class SettingInformationController { @Value("${author}") private String author; @GetMapping("/author") public String getAuthor(){ return author; } } -
添加配置信息 bootstrap.yml 文件 (打开所有的断点,才能访问到信息)
management: endpoints: web: exposure: include: '*'
将配置中心注册到注册中心
因为在实际的很大的项目之中的时候,往往需要多个配置中心来避免配置中心出现错误,导致最后新加入的服务器无法获取配置信息的情况出现,所以我们往往需要将配置中心也加入到注册中心之中。
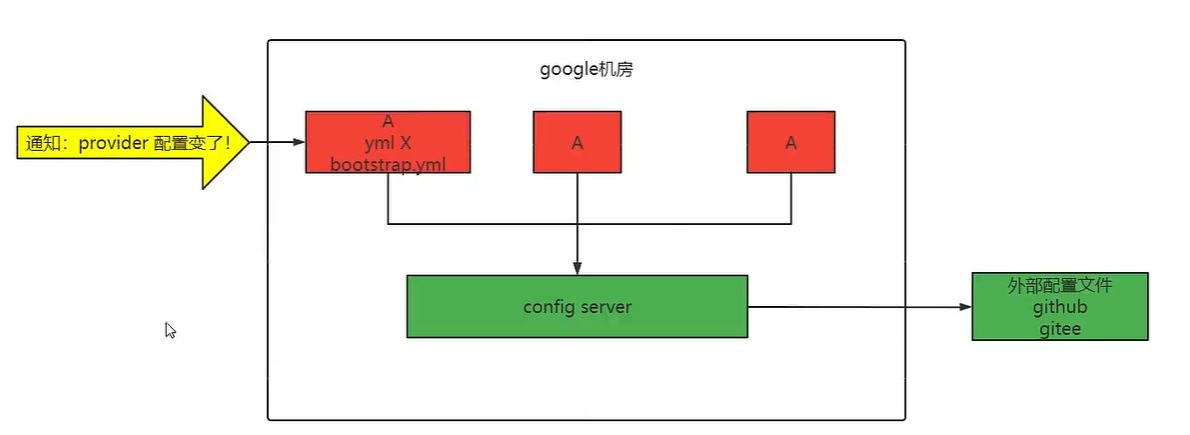
具体配置步骤
config-Client配置
-
首先需要在pom.xml文件之中添加配置信息
<!--springcloud 整合 zookeeper 组件--> <dependency> <groupId>org.springframework.cloud</groupId> <!--zk发现--> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.9</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> -
在bootstrap.yml之中添加配置信息
# 配置config-server地址 # 配置获得配置文件的名称等信息 spring: cloud: # zookeeper: # connect-string: 127.0.0.1:2181 # zk地址 config: # 配置config-server地址 # uri: http://localhost:9527 # 配置获得配置文件的名称等信息 name: provider # 文件名 profile: prod # profile指定, config-dev.yml label: master # 分支 discovery: enabled: true service-id: CONFIG-SERVER management: endpoints: web: exposure: include: '*' -
在启动类上添加配置的相关注解
@SpringBootApplication @EnableDiscoveryClient public class ConfigClientApp { public static void main(String[] args) { SpringApplication.run(ConfigClientApp.class,args); } }
config-server配置
-
在pom.xml文件之中添加相关的配置信息
<!--springcloud 整合 zookeeper 组件--> <dependency> <groupId>org.springframework.cloud</groupId> <!--zk发现--> <artifactId>spring-cloud-starter-zookeeper-discovery</artifactId> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.9</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> -
在application.yml文件之中添加配置信息
server: port: 9527 spring: application: name: config-server # spring cloud config cloud: zookeeper: connect-string: 127.0.0.1:2181 #zk地址 config: server: # git 的 远程仓库地址 git: uri: https://gitee.com/Leticia_feng/spring-cloud-config-setting.git label: master # 分支配置 -
在启动类之中添加服务提供的注解
@SpringBootApplication @EnableConfigServer // 启用 config server功能 // 开启配置中心的服务端 @EnableDiscoveryClient // zookeeper注册中心配置 public class ConfigServerApp { public static void main(String[] args) { SpringApplication.run(ConfigServerApp.class,args); } }
问题
虽然,我一直不想用eureka来作为注册中心的方式来将配置中心添加到注册中心,因为毕竟这个eureka已经被淘汰很久了,所以我尝试使用zookeeper作为eureka的上位替代,然后把Config-Client去获取相关的配置信息,在一切都很顺利的时候,配置中心已经放到了Zookeeper。但是在Config-Client尝试获取的时候报错,Zookeeper的相关类出现Bean重复的情况,经过排查发现是Config-Client配置文件中的
discovery:
enabled: true
service-id: CONFIG-SERVER
最终导致的问题。可以考虑是Zookeeper对eureka内部进行封装的时候涉及到了这部分的问题,并且查不到相关的解决方案...所以先搁浅这个问题
Bus总线中心
背景
在目前来说,总线其实本质上可以认为是一个用于实现服务之间相互交流的一个东西,Bus本身便可以充当一个媒介为各个服务提供信息交流的渠道一样的东西。结合上一个模块的话,Bus本身可以为实现Config的配置文件实时更新的一个工具。(上面提到如果要实现配置文件实时更新需要使用cmd/postman/apipost等测试工具发送Post请求使其实现更新),但在上面提及这种实现方式下,每一个服务器都需要发送一个Post请求。明显不合理...
解决思路
在前面的解决思路上,配置文件发生了变化首先是配置中心能瞬间获得相关的信息,但是Config-Client并不能获得相关的配置信息,如果想要获得就需要发送post,但如果想要一次配置多个服务器,那就需要改变这种思路,从配置中心出发,想办法让配置中心通知Config-Client更上配置文件信息。**(但是明显,我们的SpringCloud-Config并没有这样的功能,所以为了解决这个问题,可以引入我们之前学习的时候了解过的MQ机制来解决这个问题) 大概思想可以认为是:可以通过设定MQ的机制为发布订阅机制,然后设定服务器同等数量的队列机制,让服务器上去消费这个信息,进而发POST请求解决该问题。**解决思路图如下
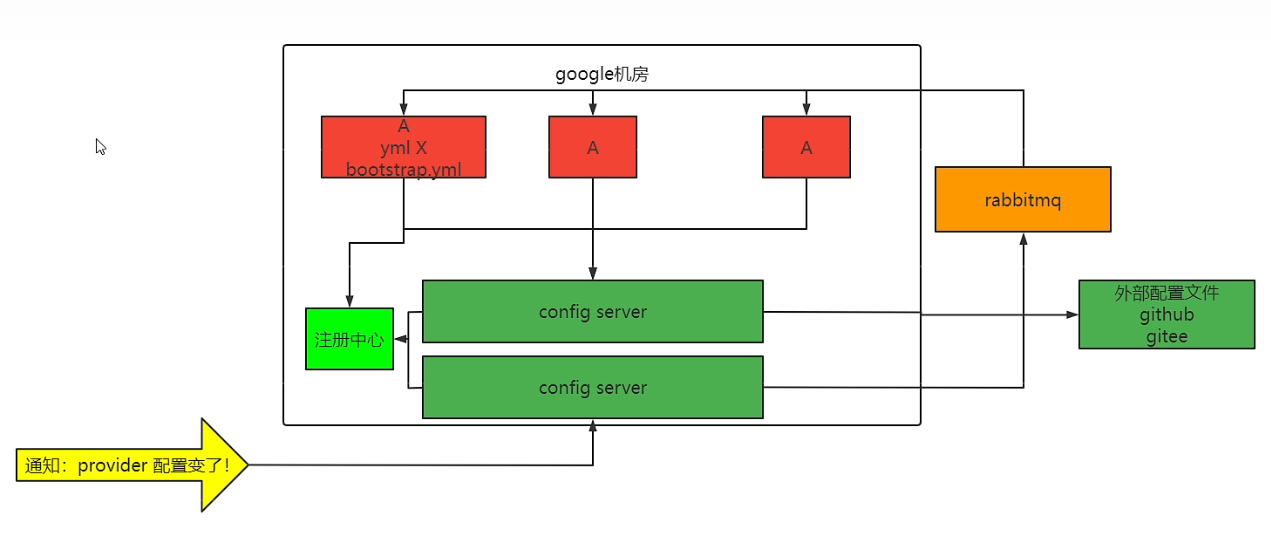
注意事项:SpringCloud Bus只能使用RabbitMQ或者Kafka来解决该问题,并不能兼容RocketMQ
RabbitMQ知识回顾
RabbitMQ的主要作用:1. 异步 2. 解耦 3. 削峰填谷
特点解释
说RabbitMQ可以做到解耦的一个原因可以和远程调用扯上一些关系,因为在直接的远程调用之中,如果对方服务器发生了异常错误,将会导致直接无法调用。在一些实时性要求较低的任务时,我们可以将这些任务的执行放到MQ之中,到需要消费的时候,再由消费者进行消费。
实现原理
其实本质上RabbitMQ其实就是AMQP协议的一种具体实现的一种产品。他是通过建立生产者和消费者之间插入了一个RabbitMQ(内有交换机、队列两大部分),RabbitMQ内部有用于交换的交换机机制。
生产者和交换机之间建立起了长链接(长链接内部会有一个channel信道机制),生产者通过channel将消息发布到交换机上。交换机则通过某种绑定机制(RabbitMQ的几种工作模式:来决定绑定的规则),将消息分发到Queue队列之中。
消费者则与某一个队列建立了长链接,然后通过长链接的channel实现信息的接收。
RabbitMQ的工作模式
**简单模式:**只放到某一个上
工作模式:放到一个队列上,但是数据的消费并非是只有一个消费者在消费,而是由多个消费者竞争消费
**发布订阅:**发到所有相关涉及到的订阅的队列上(这个队列可以是两个队列、十个队列、数百个队列、数千个队列)
**路由模式:**所谓的路由模式其实理解起来也很简单,就是RabbitMQ分发消息的时候,不再固定的将消息分发到某一个队列上,而是由具体的消息内容来决定。
**主题模式:**而主题模式更可以认为是路由模式的扩展版本,即是当路由模式下,路由太多了难以实现配置,很容易发生错误的情况下,就可以使用通配符的方式实现路由转发的效果
**RPC远程调用:**其实就是通过RabbitMQ的方式来实现远程调用,即服务调用方,通过远程调用调用服务提供方的接口,并将相关的执行信息放到回调队列之中,提供给调用方信息(为了避免出现回调信息问题,可以通过使用唯一标识ID的方式来做区分)
Bus具体配置步骤
-
往config-server和config-client的pom文件之中添加依赖
<!-- bus --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bus-amqp</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> -
分别在 config-server (application.yml)和 config-client (bootstrap.yml)的yml文件中配置RabbitMQ
config-server的yml文件
server: port: 9527 spring: application: name: config-server # spring cloud config cloud: zookeeper: connect-string: 127.0.0.1:2181 #zk地址 config: server: # git 的 远程仓库地址 git: uri: https://gitee.com/Leticia_feng/spring-cloud-config-setting.git label: master # 分支配置 # 配置rabbitmq的信息 rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: / # 暴露bus的刷新端点 management: endpoints: web: exposure: include: 'bus-refresh'config-client的yml文件
# 配置config-server地址 # 配置获得配置文件的名称等信息 spring: cloud: # zookeeper: # connect-string: 127.0.0.1:2181 # zk地址 config: # 配置config-server地址 uri: http://localhost:9527 # 配置获得配置文件的名称等信息 name: provider # 文件名 profile: prod # profile指定, config-dev.yml label: master # 分支 # 因为SpringCloud并不支持Zookeeper实现配置中心注册到注册中心,所以,这里为了后续可以继续使用该子模块,先注释 # discovery: # enabled: true # service-id: CONFIG-SERVER # 配置rabbitmq的信息 rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: / management: endpoints: web: exposure: include: '*' -
需要注意的是config-server的application.yml配置文件之中需要添加 暴露bus-refresh端点才能保证运维能过往配置中心中发送相关信息
# 暴露bus的刷新端点 management: endpoints: web: exposure: include: 'bus-refresh' -
此时我们如果尝试打开项目,我们可以在RabbitMQ management的web网站上打开Queues上看到多了两个Queue,以springCloudBus.anonymous开头的队列(一个是配置中心的队列,一个是客户端的队列) ,当我们去打开exchange可以看到有一个springcloudbus命名的交换机,该交换机的类型为topic类型
总结就是:会自动创建对应的Queue和Bus Exchange
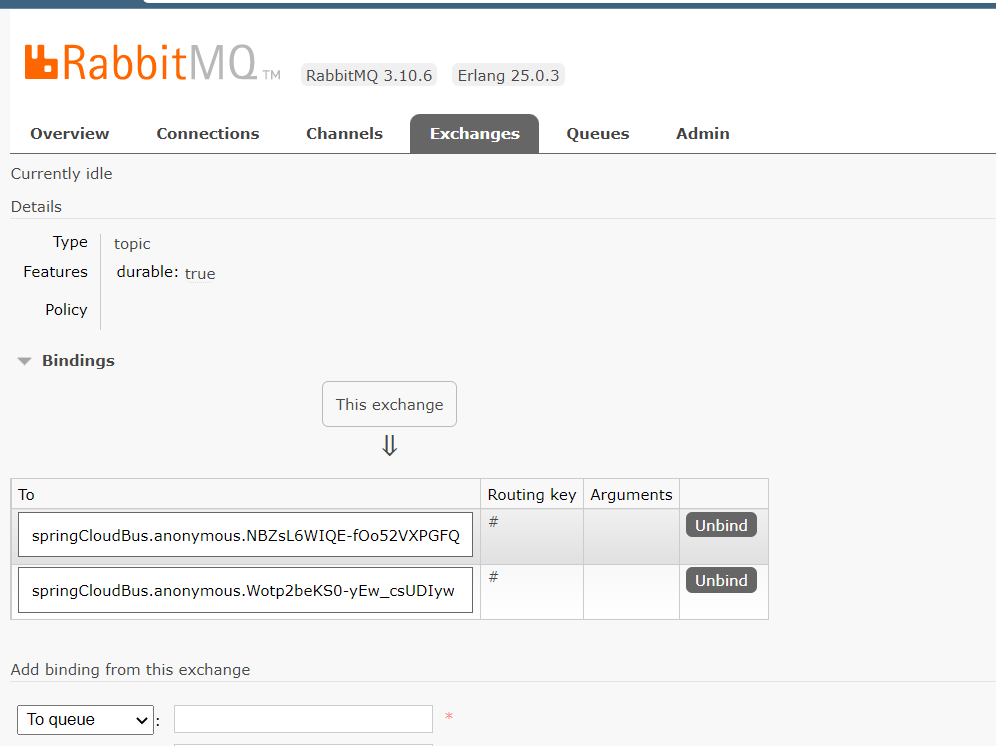
此时,如果我们想要为全体服务器更新配置文件,只需要给配置中心发送对应的POST请求即可实现相关的需求
curl -X POST http://localhost:9527/actuator/bus-refresh
Stream消息驱动
配置中心通过使用Bus总线所解决的问题是,我们可以通过一次发送POST请求来实现对所有的服务器进行配置。
新问题:如果有一天,技术框架之中使用的消息队列的技术已经过时了,要更新为新的消息队列的技术的话,我们的代码就需要全部重新修改,总的来说,可以总结为一点。耦合度太高了,不行。
解决思路:没有什么东西是不能通过加多两层的方式来解决的。所以其实本质上SpringCloud提出的这个解决方案SpringCloud-Stream其实就是通过在消息队列和服务提供方和服务消费方之间加层的方式来解决的。可以简单的认为就是他做了加层使得我们发送消息与消息队列之间是无感知的方式来实现的。我们后续如果想要更新消息队列这个过程都可以是动态实现的。
其实就像JDBC一样。我们操作数据库时,再也和数据库本身是什么数据库无关了。
SpringCloud-Stream当然也有他的缺点,SpringCloud-Stream目前只支持使用RabbitMQ和Kafka两种消息队列,其他都不支持。
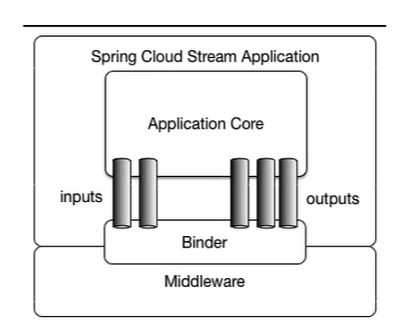
原理解析
其实就是在MQ之前加入了绑定器Binder以及两种管子,一种管子的名称叫做inputs,另外一种管子叫做outputs,至于我使用到的到底是RabbitMQ还是Kafka我不用管了。output和input其实就是发送消息和接收消息的channel,一个内置的是Source接口,另外一个内置的是Sink接口。
消息生产者端 Stream-provider
具体步骤
-
在Stream-provider的pom配置文件之中添加相关的依赖信息
<dependencies> <!--spring boot web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- stream --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> </dependencies> -
在Stream-provider的配置文件application.yml,当然如果想要使用配置中心,也可以在配置中心对应的配置文件之中进行配置
server: port: 8000 spring: cloud: # 配置 Stream 的绑定器,发送的 rabbitMQ 地址以及接收的 exchange stream: # 定义绑定器,绑定到哪个消息中间件上 # 配置完这部分的配置之后,Stream中的 binder 就可以和RabbitMQ产生联系了 binders: leticiafeng_binder: # 自定义的绑定器名称 type: rabbit # 绑定器类型 environment: # 指定mq的环境 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: / # 指定 Binder 要发送的交换机 bindings: output: # channel名称 binder: leticiafeng_binder #指定使用哪一个binder destination: leticiafeng_exchange # 消息目的地 -
在Stream-provider之中建立用于产生消息,发送消息的Binder绑定器的工具类 Messageproducer
@Component @EnableBinding(Source.class) // stream的发送者 public class MessageProducer { @Autowired MessageChannel output; // 一定要叫做output,不然会报错 public void send(String msg){ // 需要注意的是 send 本身上是一个 Message 为参数的方法,所以在实际的调用过程之中 // 需要使用MessageBuilder来将String信息转换为Message类型的信息 output.send(MessageBuilder.withPayload(msg).build()); System.out.println("MessageProducer 确实发送了消息了"); } } -
最后在ProducerController控制台编写相关的接口,并且调用发送消息的工具类,实现调用功能
@RestController @RequestMapping("/stream") public class ProducerController { @Autowired MessageProducer messageProducer; // 业务逻辑 @GetMapping("/send") public String send(){ //发送消息 String msg = "使用了Stream来实现了消息的,实现了实际开发代码和消息队列脱钩"; messageProducer.send(msg); return "success!"; } }
总结
当我们写完Provider的代码之后,可以尝试访问localhost:8000\stream\send路径尝试去调用相关的接口,来发送信息,可以在RabbitMQ的Management之中发现,RabbitMQ已经成功接收到Stream Provider发送的数据。而我们的代码上没有涉及到RabbitMQ相关的特有信息,说明我们已经实现了脱耦。但是,因为我们的交换机没有绑定好队列,所以我们的消息最终变为了死信消息,并没有真的被队列缓存。
消息消费者端 Stream-consumer
首先需要注意的是,Stream-consumer程序本身和Stream-provider两个程序本身是没有任何关系的,所以两个程序可以都使用同一个名字的绑定器,但实际上在微服务架构之中,这两个binder并非是同一个绑定器。
其次,在配置文件之中Stream-provider和Stream-consumer两者的bindings中绑定的交换机各不相同,provider绑定的是output的channel的交换机,consumer绑定的是input的channel的交换机,意思是从绑定的交换机身上取得消息。
最后需要注意的是,我们在框架之中可以发现,我们其实在整个过程之中没有建立队列并对我们自己建立的队列,监听,但实际代码运行时,我们可以发现,会自动的产生一个队列。
具体步骤
-
在stream-consumer的pom.xml配置文件之中添加配置信息
<dependencies> <!--spring boot web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- stream --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> </dependencies> -
然后在consumer的配置文件application.yml之中添加相关的配置信息
server: port: 9000 spring: cloud: stream: # 定义绑定器,绑定到哪个消息中间件上 binders: leticiafeng_binder: # 自定义的绑定器名称 type: rabbit # 绑定器类型 environment: # 指定mq的环境 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest virtual-host: / bindings: input: # channel名称 注意这里是input和生产者不一致 binder: leticiafeng_binder #指定使用哪一个binder destination: leticiafeng_exchange # 消息目的地 -
创建信息消费类 MessageListener
@Component @EnableBinding(Sink.class) // 这个类才是Stream的消费者监听类 public class MessageListener { @StreamListener(Sink.INPUT) //告诉程序这个是一个监听方法,只要接收到消息,马上执行下面代码 public void receiveMsg(Message message){ // 业务逻辑 (拆开payLoad看到内部信息) System.out.println(message.getPayload()); } }
到此,Stream的介绍基本结束。
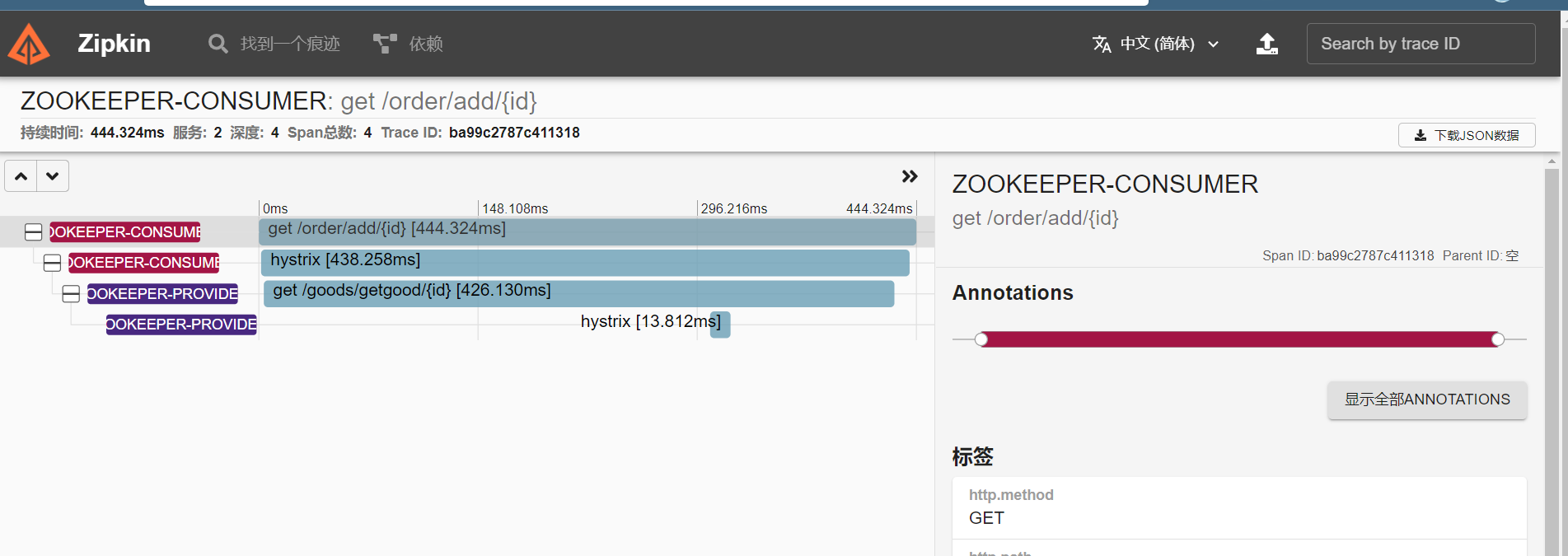
Sleuth分布式请求链路追踪
在实际的大规模的分布式系统下,一个用户请求往往会产生多个的服务调用,而多个服务调用就很容易产生调用过程、信息不清晰等一系列问题。如果想要看清楚调用的信息,那就需要使用链路追踪的功能。
获得整个请求的过程和构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
主要功能
- 耗时分析
- 可视化错误
- 链路优化
Sleuth主要实现的收集信息和数据,但是它并不能为我们提供可视化的展示等功能,所以这个时候就需要我们一个新的技术Zipkin出现。
Zipkin是Twitter的一个开源项目,致力于收集服务的定时数据,用以解决微服务架构之中的延迟问题,包括有数据的收集、存储查询和展示。
主要步骤
-
首先需要去zipkin官网,去下载一个相关的jar包Quickstart · OpenZipkin,下载完毕之后,就可以通过cmd,以java -jar的方式启动,即可。
如果想要访问相关的Web网站,可以通过访问http://localhost:9411/zipkin/,即可查看当前Zipkin的相关执行信息
(但是目前,我们只打开了Zipkin的相关服务,并未正式打开,但是这个jar,是我们可以成功看到Zipkin收集到的信息的关键。
-
为了实现信息的收集,我们需要到微服务之中的人一个服务提供者和服务消费者之中添加相关的依赖包,才能保证我们的服务能收到微服务之中所有人的调用信息。
例如提供者或者消费者:zookeeper-consumer / zookeeper-provider之中的pom文件之中可加入
<!-- 使用zipkin,就包含了sleuth --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -
然后只需要在provider和consumer的配置文件yml之中加入相关的配置项(或者可以使用配置中心来实现),即可实现配置,后续只需要在Zipkin的web页面打开便可以看到相关的调用信息
zookeeper-provider的配置文件
server: port: 8004 spring: application: name: zookeeper-provider cloud: zookeeper: connect-string: 127.0.0.1:2181 # zk地址 zipkin: base-url: http://localhost:9411/ # 设置zipkin的服务端路径 sleuth: sampler: probability: 1 # 采集率 默认 0.1 百分之十。 organization: LeticiaFENGzookeeper-consumer的配置文件
server: port: 8005 spring: application: name: zookeeper-consumer cloud: zookeeper: connect-string: 127.0.0.1:2181 # zk地址 zipkin: base-url: http://localhost:9411/ # 设置zipkin的服务端路径 sleuth: sampler: probability: 1 # 采集率 默认 0.1 百分之十。 (如果设置太大,收集率太大了,不好用;但是我们只是学习,设置0.1容易没有数据) ribbon: ConnectTimeout: 4000 # 连接超时时间 默认1s ReadTimeout: 10000 # 逻辑处理的超时时间 默认1s logging: level: com.leticiafeng: debug # 开启feign对hystrix的支持 feign: hystrix: enabled: true -
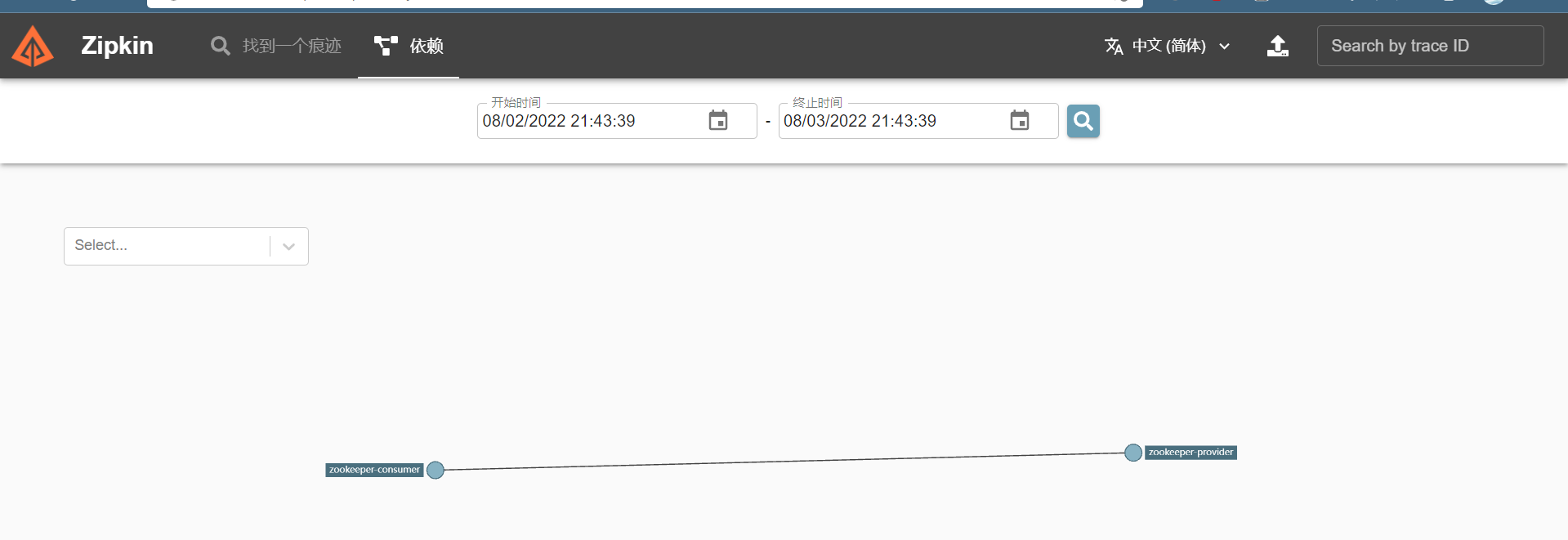
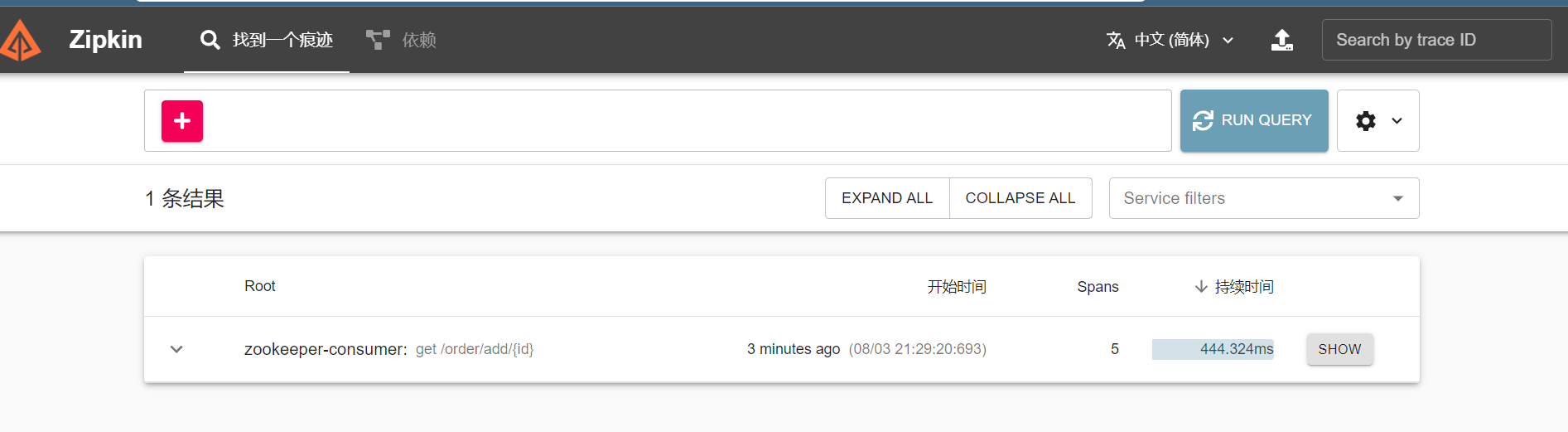
打开Zipkin的web页面,便可以看到收集到的信息,还可以看到依赖信息
依赖关系图