ELK日志架构
首先要明确一点的是,ELK需要以下多个工具组件来结合才能使用:
-
Filebat 轻量级的日志收集工具
-
Logstash,主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式
一般分为两个版本, client 端我们会通过 Filebat 代替;而 server 端则还是使用 Logstash 方实现,并存放到ES之中进行记录。
-
Elasticsearch,本身是一个开源的分布式搜索引擎
-
Kibana,图形化界面协助分析、处理日志数据
ELK几种常见的架构模式
架构一
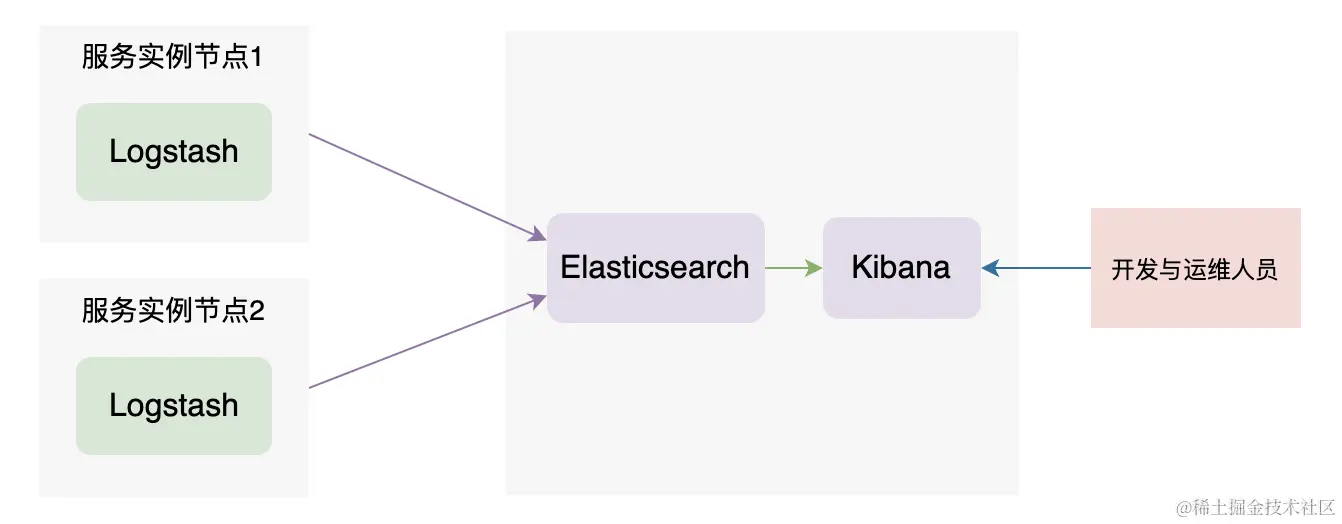
elk架构是最基础的elk初代状态,但是他的问题也非常明显。上图的是一个非常简单的ELK架构模型,也就是通过在服务节点上通过使用 Logstash 来收集各个服务产生的日志,然后再发送到ES之中进行存储,我们则可以通过Kibana来查询分析我们的ES架构。但是这种方式的缺陷也非常明显,需要在每一个服务上搞一个Logstash来收集并发送消息到我们的目标ES。
架构二
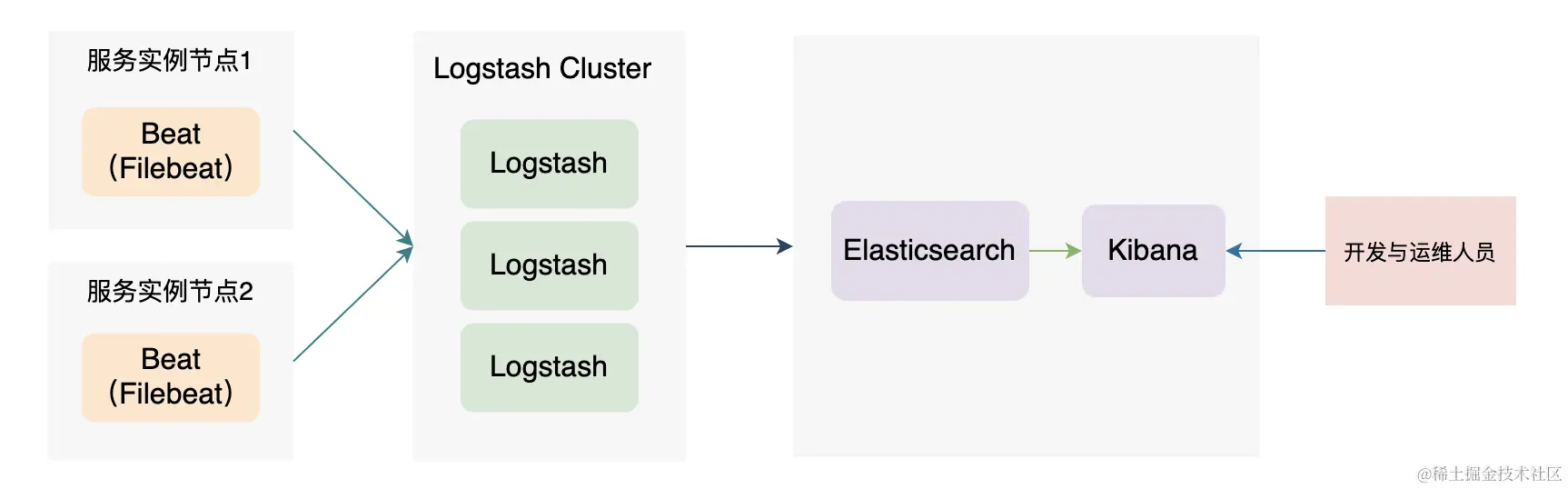
基于最初的ELK架构,很快就衍生出EFK架构,也就是将Logstash完全由Filebeat替换掉。但是这样其实也不太完美,更加完美的做法其实就是将Logstash Cluster作为中间层,组成EFLK。
在上图之中,为了降低性能的消耗的问题,我们将客户端手机数据的部分修改为 Filebeat,然后让Filebeat会将日志数据发送到Logstash上,由多台Logstash组成的Logstash Cluster将会把数据转发到 Elasticsearch 之中,并且Kibana提供针对ES数据的收集和处理工作,帮助我们做分析。
看起来这个架构已经相当好了,似乎没啥问题;但其实如果考虑上微服务在大数据量和请求量的冲击下,可能会大量数据日志导致Logstash Cluster之中的服务发生崩溃。这势必会导致我们的日志服务本身不稳定的问题,这种情况下,我们就需要考虑引入MQ队列的方式来优化。
架构三

就跟案例二的介绍说的一样,因为在正常情况下使用,架构二应该是能满足需要的,但问题在于我们大概率不是真的就一致都在平稳状态,面对请求爆发的时候我们原先的处理往往就不能满足需要了,在这种情况往往就需要加入Kafka来解决这个问题。上图的就是较为常见的架构模式。也就是ELFK + Kafka做缓冲的架构图。
ELK架构搭建
下面按照顺序先后安装 Kafka、Filebeat、Logstash 三大组件。
Logstash
还记得上面的介绍吗?Logstash在不需要filebeat的情况下其实也能完成工作,提供完整的日志采集服务将采集到的日志交给ES进行处理。所以在Logstash之中其实是包含了filebeat的工作的,以下先做一些简单的介绍。
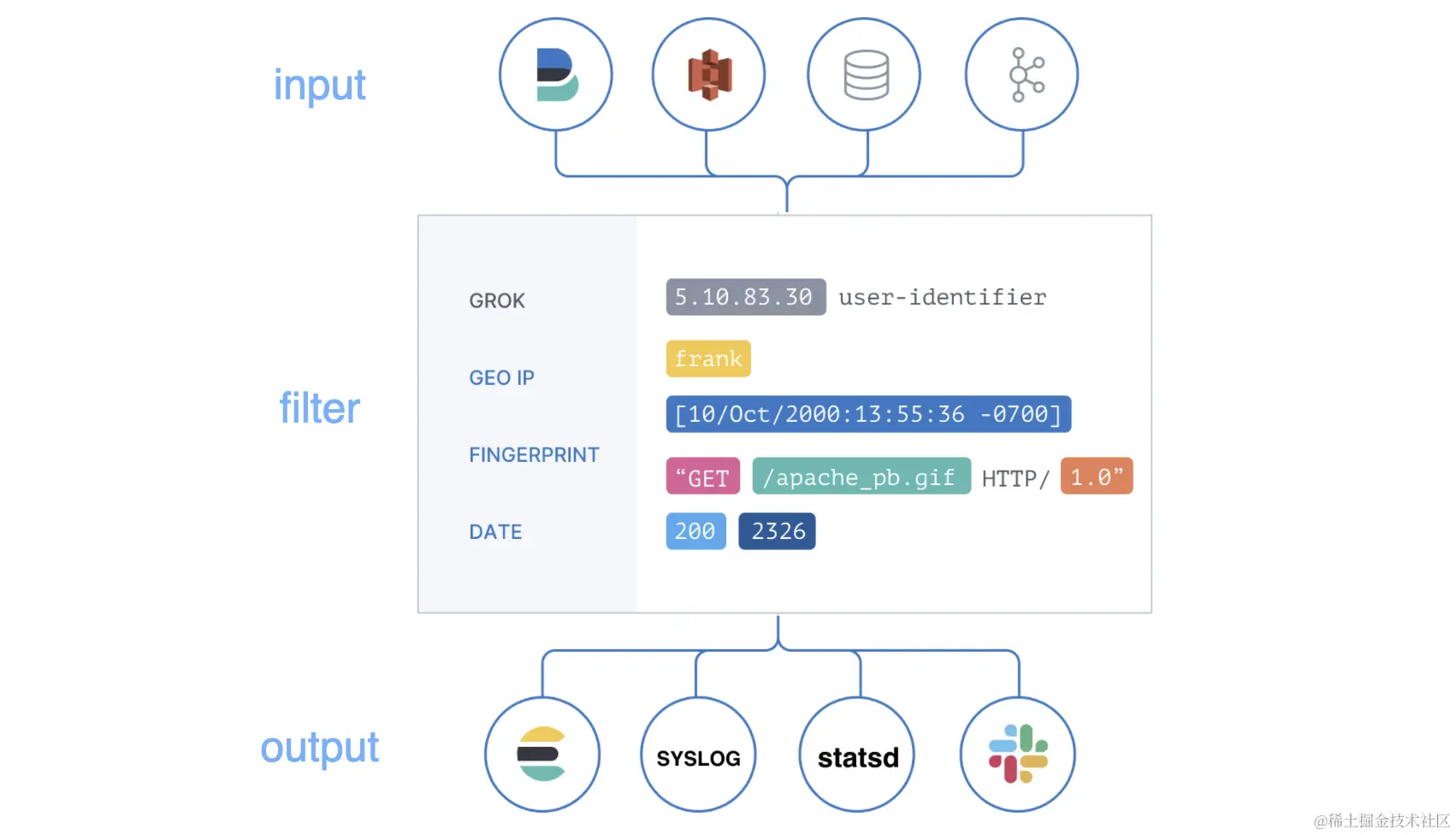
Logstash会通过input线程找到目标的日志文件,然后通过日志文件本身的监听,将日志数据流交给filter进行处理,并将最终处理的结果交给output,显然的output不仅仅只会用es。
所以从整个流程的角度来看,我们Logstash的处理流程可以概括为以下的步骤:input -- > event --> filter event --> output。
- input:通过input我们可以将数据从源之中不断采集
- filter:数据采集、处理操作,可以将数据增加 / 删除其中的某些字段 (也就是对数据进行处理)
- output:通过output可以将处理后的数据保存到其他的系统之中。
- event:在管道之中流转的数据,可以通过使用Codes Plugins来对数据做编码和解码工作,比较流程的格式有 json 和 msgpack、plain(text)等
除了这几个基础的使用以外,Logstash还支持了一些input、filter、output等众多的相关插件 (提供针对不同的数据源相关的插件数据获取,包括有kafka topic、服务日志、mysql日志等),因为篇幅问题这里不会过多的赘述。
安装Logstash
# 下载 tar 包 (300+M,用wget准备下过年)
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.13.0-linux-x86_64.tar.gz
# 解压
tar xvf logstash-7.13.0-linux-x86_64.tar.gz
# 重命名
mv logstash-7.13.0 logstash
增加配置
与一般的中间件的配置有所不同的是 Logstash 的配置文件需要我们自己创建,名字也是自定义的,我们可以取任意名字,当然了为了规范一些,一般来说会使用 kafka-topic_name 或者是 pipeline 的名字。并且更为规范的话,一般来说会存放到以下两个位置:
- /etc/logstash/conf.d --- Linux (或者 LOGSTASH/config)
- {LOGSTASH_HOME}/config --- Windows
配置的文件,我们可以构建起来 kafka-topic_name.conf / .yml 或者 pipline.conf / .yml 又或者是 server.conf / .yml。至于内部的配置,可以参考提供的例子。
# 将以下内容写入到到 OrderServiceLog.conf 中
input { # 使用kafka插件从kakfa的topic之中获取日志
kafka {
bootstrap_servers => ["localhost:9092"] # kafka path
topics => ["order_service"] # kafka topic 名 (可以指定多个 topic)
codec => "json" # kafka 消息格式 (默认是 plain)
auto_offset_reset => "latest" # kafka log文件偏移量
decorate_events=> "basic" # 是否要携带kafka的元数据
group_id => "logstash01" # kafka消费组id,以group作为单位消费消息
}
}
filter {
grok {
match => { "message" => "(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]" } # 使用grok提取日志产生的时间和日志级别
}
mutate { # 实现日志级别的转换
lowercase => [ "level" ]
remove_field => ["beat"]
}
}
output {
elasticsearch {
hosts => ["https://localhost:9211"] # 目标ES地址
index => "%{[@metadata][kafka][topic]}_%{+YYYY-MM-dd}"
user => "elastic" # es账号和密码
password => "123456"
ssl => true # 是否使用ssl
ssl_certificate_verification => false
cacert => "/home/ubuntu/ES/logstash/config/es_ca.pem" # SSL验证文件 如果没有SSL可以去掉该行
}
}
上面已经基本介绍了大部分的参数的配置效果和内容,但显然的这还不够,下面将会补充一些信息
input的插件配置
-
auto_offset_reset:除了可以指定lastest以外,还可以配置为earliest和 none。
- lastest:相当于从最后的消息开始消费
- earliest:相当于从最初的消息开始消费 (如果之前消费过那么,这里的效果等同于重新消费--重放)
- none:使用原先默认的offset,但是如果之前没有offset可以使用,这样配置就会报错
-
decorate_events:是否在转发消息的时候携带消息在es之中的元数据,默认的配置是 none,需要使用的时候需要配置为basic 或者 extended才会生效。
如果要知道这两者的配置有什么区别需要知道kafka元数据的有哪些:
在配置为 basic 之后,Kafka的元数据会包括有:
[@metadata][kafka][topic]: Kafka 主题名称[@metadata][kafka][consumer_group]: 消费者组名称[@metadata][kafka][partition]: 分区号[@metadata][kafka][offset]: 消息在分区中的偏移量[@metadata][kafka][key]: 消息的 key(如果存在)[@metadata][kafka][timestamp]: 消息的时间戳
而如果配置为extended的话,kakfa的元数据还会包含有以下的内容:
[@metadata][kafka][consumer][client_id]: 消费者客户端 ID[@metadata][kafka][consumer][partition_assignment_strategy]: 分区分配策略[@metadata][kafka][consumer][request_timeout_ms]: 请求超时时间(毫秒)[@metadata][kafka][consumer][session_timeout_ms]: 会话超时时间(毫秒)[@metadata][kafka][consumer][max_poll_interval_ms]: 最大轮询间隔(毫秒)[@metadata][kafka][consumer][rebalance_timeout_ms]: 重平衡超时时间(毫秒)[@metadata][kafka][consumer][committed_offset]: 已提交的偏移量
filter插件配置
filter {
grok {
match => { "message" => "(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]" } # 使用grok提取日志产生的时间和日志级别
}
mutate { # 实现日志级别的转换
lowercase => [ "level" ]
remove_field => ["beat"]
}
}
filter之中使用提取日志产生的时间和日志级别,并且通过mutate来将日志级别的内容做转换,并且取出掉所有beat相关的字段。
grok
在示例之中,我们将match的匹配正则其实匹配的是我们常见的日志格式。
[2022-04-07 12:07:50,335] [ERROR] [ActorSystemImpl] [default-dispatcher-4] - 登录异常,账号或者密码错误!
(?m)^\[(?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]%{SPACE}\[(?<level>[A-Z]{4,5})\]
其中 (?m) 代表的是m条日志输出,而 (?<log_date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})显然匹配的是日期时间,%{SPACE}其实是区分大小写的识别,(?<level>[A-Z]{4,5})的实际匹配就是匹配4到5个大写字符
这里可以稍微补充一下
d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3}
d{4}代表的是四位连字符 (代表年份)
-代表的是字符
\s代表空白字符
显然的就可以知道,这个字符串匹配的是日期时间格式,精确到秒后三位 2023-04-15 10:30:45,123
如果想要了解更多,不妨可以参考一下官方文档之中的介绍:Grok filter plugin | Logstash Reference 8.15 | Elastic
mutate
mutate其实就是针对我们的匹配字段做一些修改操作,比如执行字段重命名、字段内容替换、大小写转换等功能问题。这个比较简单,如果想要了解更多可以参考官方文档。Mutate filter plugin | Logstash Reference 8.15 | Elastic
output插件配置
output插件其实基本就没啥好聊的了,文档本身介绍的就是ELK日志结构,在我们示例之中使用的更是EFLK架构,那毫无疑问日志最终是要被推送到ES上的,因此output指向的必然是ES。在上文示例之中就是以下的内容:
output {
elasticsearch {
hosts => ["https://localhost:9211"]
index => "%{[@metadata][kafka][topic]}_%{+YYYY-MM-dd}"
user => "elastic"
password => "elastic"
ssl => true
ssl_certificate_verification => false
cacert => "/home/ubuntu/ES/logstash/config/es_ca.pem"
}
}
- hosts,ES 集群的地址,如果指定一个数组的话会负载到各个节点去。
- index,指定保存数据的索引,其中我们使用了 %{[@metadata][kafka][topic]} 来获取数据是从哪个Kafka topic 来的,需要注意 Kafka input 插件需要 设置 decorate_events 为 basic 或者 extended 才可以生效。使用 %{+YYYY-MM-dd} 来获取当前日期。最终示例中索引的名字为 order_service_${date}。
- ssl,开启使用 SSL 连接到 ES 集群。
- ssl_certificate_verification,是否开启证书认证,这里设置 false。
- cacert,指定链接到 ES 集群的 .cer 或者 .pem 证书。
启动logstash
nohup ./bin/logstash -f config/${udf_config_filename}.conf >> ./run.log 2>&1 &
// nohup ./bin/logstash -f config/kafkaLogEFLK.conf >> ./run.log 2>&1 & // case use
Kibana (中间层)
我们可以先安装并配置Kafka (wget命令有点问题,建议是自己用windows下好,再搞过去)
# 使用 wget 下载 (实际上不推荐wget,慢的要死)
wget --no-check-certificate https://dlcdn.apache.org/kafka/3.8.0/kafka_2.12-3.8.0.tgz
tar xvf kafka_2.12-3.8.0.tgz
mv kafka_2.12-3.8.0.tgz kafka
修改配置
在 kafka/config/server.properties 中加入以上配置即可,更多 kafka 调优配置你需要参考其官方文档。
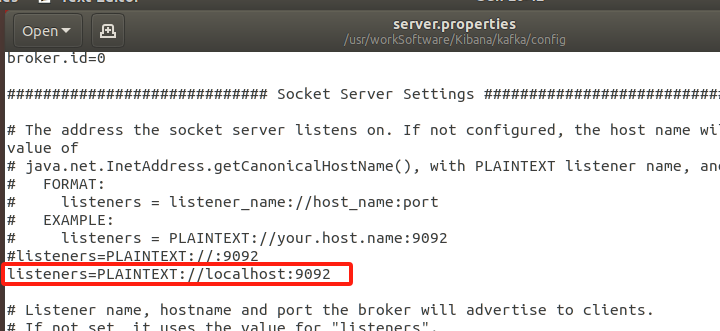
listeners=PLAINTEXT://localhost:9092
启动Kafka
创建一个脚本文件 start_kafka.sh,并填入以下的信息
function kill_all_app_by_name()
{
pid=`ps -ef | grep $1 | grep -v "grep" | awk -F" " '{print $2}'`
for i in $pid; do
kill -9 $i
done
}
kill_all_app_by_name "kafka.Kafka"
kill_all_app_by_name "QuorumPeerMain"
./bin/zookeeper-server-start.sh ./config/zookeeper.properties >> ./logs/zk.log 2>&1 &
sleep 1
./bin/kafka-server-start.sh ./config/server.properties >> ./logs/kafka.log 2>&1 &
如果只是先做一个简单的测试,我们可以先创建一个简单的topic,供后续检查
// 创建出一个简单的Kafka服务
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic order_service
// 如果想要测试,还可以在终端之中启动生产者 (kafka路径下开启新的终端)
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic order_service
// 如果想要测试,还可以在终端之中启动消费者 (kafka路径下开启新的终端)
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic order_service
Filebeat (服务端)
所谓的FIleBeats其实非常简单,就是单纯一个本地日志采集程序,将本地的日志结果采集起来最终交付给外部的类似于Kafka、Logstash、ES等外部服务。 (需要注意的是,其实Filebeat本身是ES开发的一个工具,它本身内部包含有多个beat组件,针对不同的场景都有做日志处理,只不过其中最出名的在Linux系统下跑的是Filebeat罢了)
如果对其他的beat感兴趣,可以参考es官方提供的beats的介绍页面
Beats:Elasticsearch 的数据采集器 | Elastic
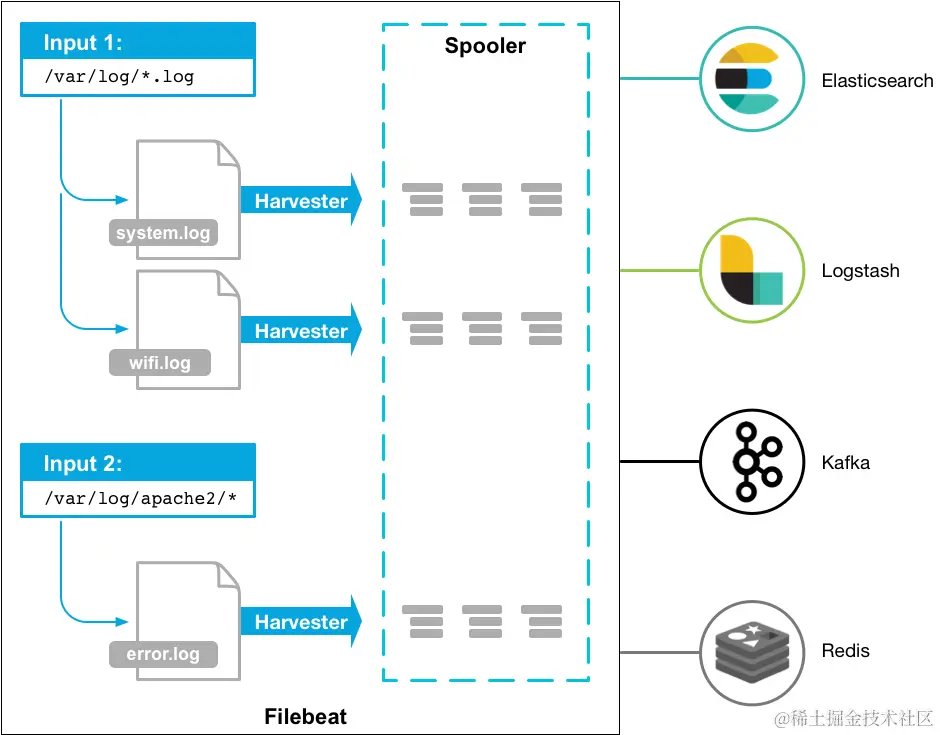
如同上图所示,其实Filebeat由两个部分组成,首先是Input和Harvester,Filebest会开启一个或者多个Input线程来获取本地日志文件,每当找到一个实际需要监听的日志文件,就会自动的开启一个Harvester来监听和读取这些日志文件的内容,并且将日志的内容实时的转发给 libbeat ,libbeat则通过聚合日志时间和发送聚合后的数据到指定的外部服务之中。
更加当然的,ES毕竟作为一个完全开源的技术(毕竟基于Lucene是Apache的),还提供了官方的文档支持你做自定义的处理。
安装Filebeat
跟Kafka类似的,我们可以通过 wget 下载 (这个可以用wget,因为不大)
# 使用 wget 下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.0-linux-x86_64.tar.gz
# 解压
tar xzvf filebeat-7.13.4-linux-x86_64.tar.gz
# 重命名
mv filebeat-7.13.4-linux-x86_64 filebeat
修改配置
filebeat的配置叫做filebeat.yml,但是需要注意的是,官方提供的示例过于完整了,一般来说用不到这么多的配置,我们可以先将官方提供的配置示例暂时保留起来(备份),然后先按照底下这个最简单的配置方式来配置。(备份完毕之后,可以先把官方配置全删了,直接粘贴即可)
filebeat.inputs:
- type: log
enabled: true
paths:
- server.log # 改变到你的日志路径 (case use: /usr/workSoftware/kafka/kafka.log)
#fields:
# level: debug
# review: 1
multiline.type: pattern
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["kafka server path"] # kafka服务的地址
# message topic selection + partitioning
topic: 'kafka topic name' # kafka用来暂存日志的 topic
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
其中有一段配置比较重要,这里着重介绍一下 (需要注意的是,filebeat的目的是区分出一个日志事件的开始和结束,并将其作为一个完整的事件交给外部的服务,因此需要以下的配置来帮助他识别出日志的关系)
- multiline.type,默认值为 pattern,定义了使用何种方式聚合数据。pattern 是使用正则匹配,其他选项为 count,将会聚合指定行数的日志为一个事件。
- multiline.pattern,指定匹配日志的正则表达式,支持的正则策略可以参考官方文档。
- multiline.negate,定义是否否定 multiline.pattern 定义的正则,默认是 false。
- multiline.match,定义如何合并多行日志。可选项为 after 或者 before。
配置的效果就是:使用正则表达式(type: pattern),如果与正则(^[)不匹配(negate: true)的行会追加到先前的一行后面(match: after)。如果与正则匹配的话,前面所有追加的内容将成为一个完整的日志事件,随后将会被发送到 output 对应的服务中,而当前匹配行将成为一个新日志事件的起始行。
# 修改权限 (也可能不用修改,建议先试试直接启动)
chmod go-w filebeat.yml
# 前台启动
./filebeat -e
# 后台启动,日志在 logs 目录下
./filebeat -c filebeat.yml >> /dev/null 2>&1 &
最后提醒一下,到这里能这么顺利的前提是,你必须事先对ES集群做了安全验证等一系列处理,也就是配置cerebro、kibana、es集群密码、ca验证文件等,这个部分可以参考其他的文档,或者自己搜索也行,很常见。
简单使用ELK
为了更有意思一些,我监听的目标是kafka本身会生成kafka.log日志。当我在shell之中往kafka发送消息的时候,成功在cerebro中看到新生成的索引
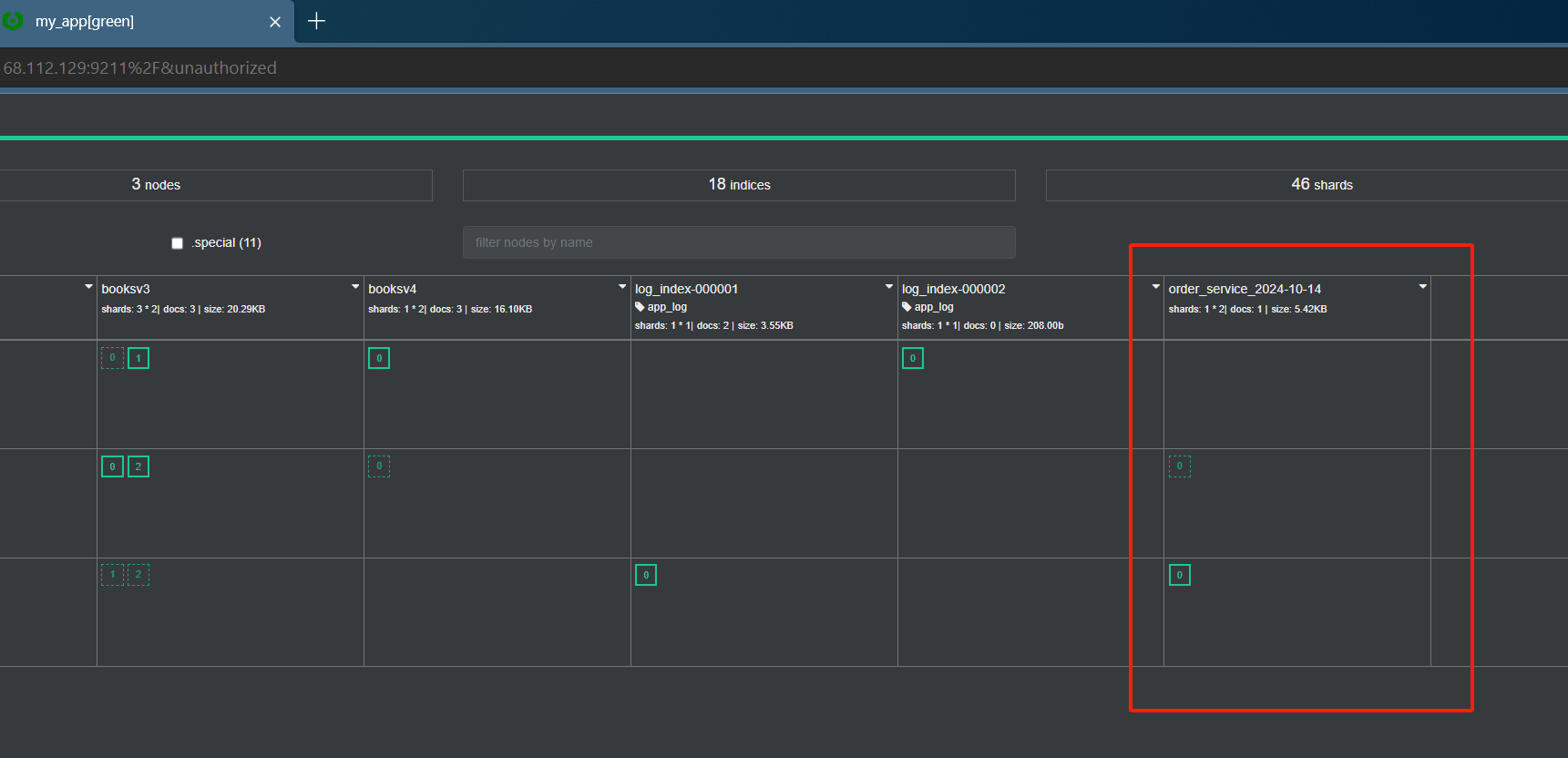
通过终端,我尝试发送了多条数据给消费者获取。而filebeat成功将kafka.log的数据采集交给kafka的order_serice topic,并交付给Logstash,最终提交了ES,也成功在cerebro中查看到新生的索引。
那问题来了,这也不方便啊...
这就需要我们使用 kibana 了
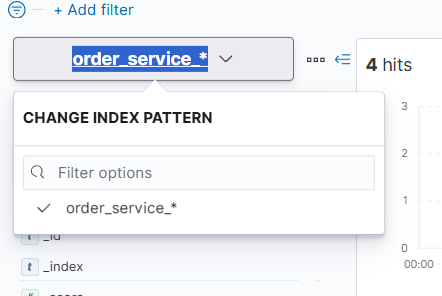
-
创建索引pattern,让kibana过滤出日志索引
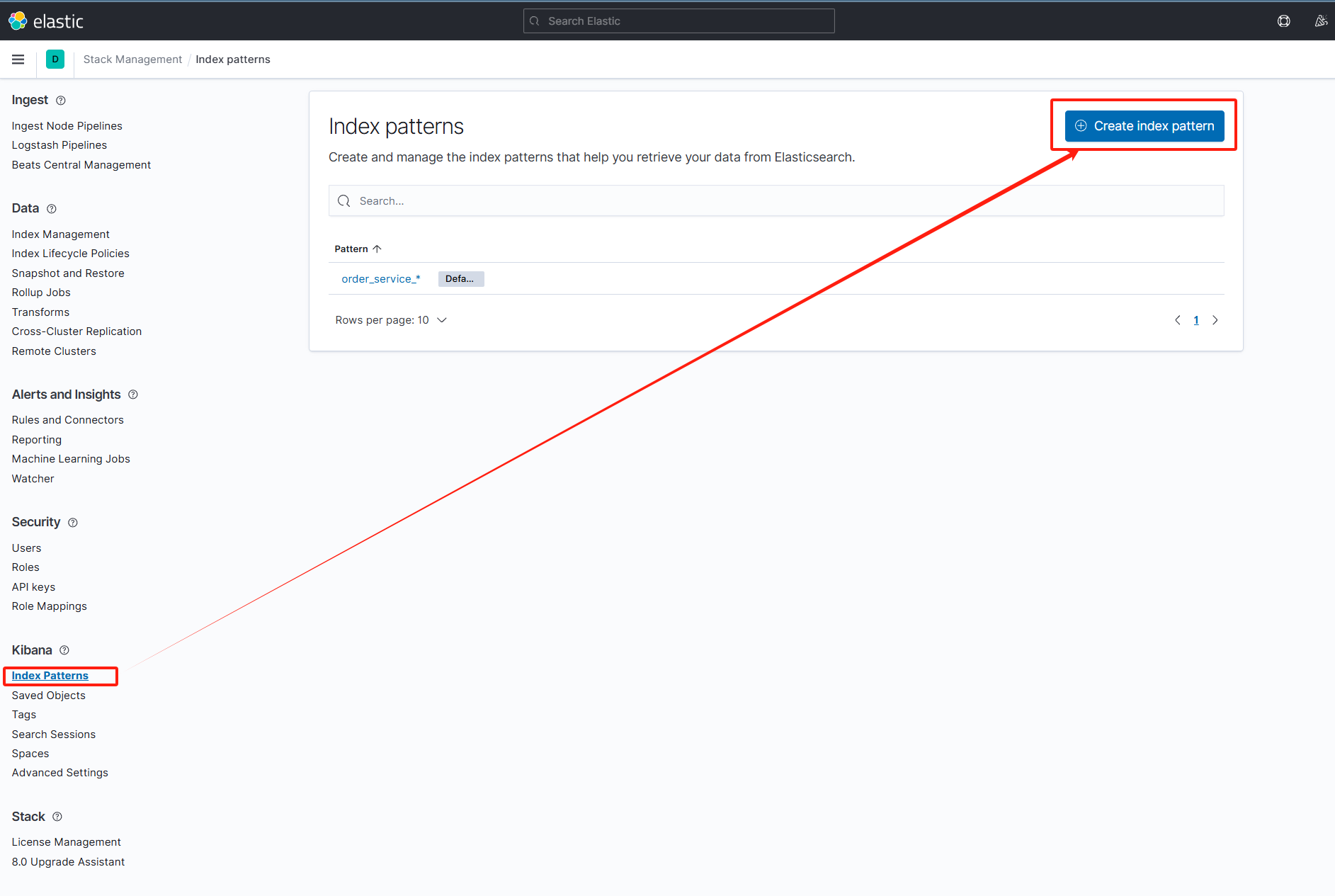
根据我们在 Logstash 自定义的配置文件之中编写的 index pattern 结合实际的 pattern 编写我们的日志索引的 patterns 即可
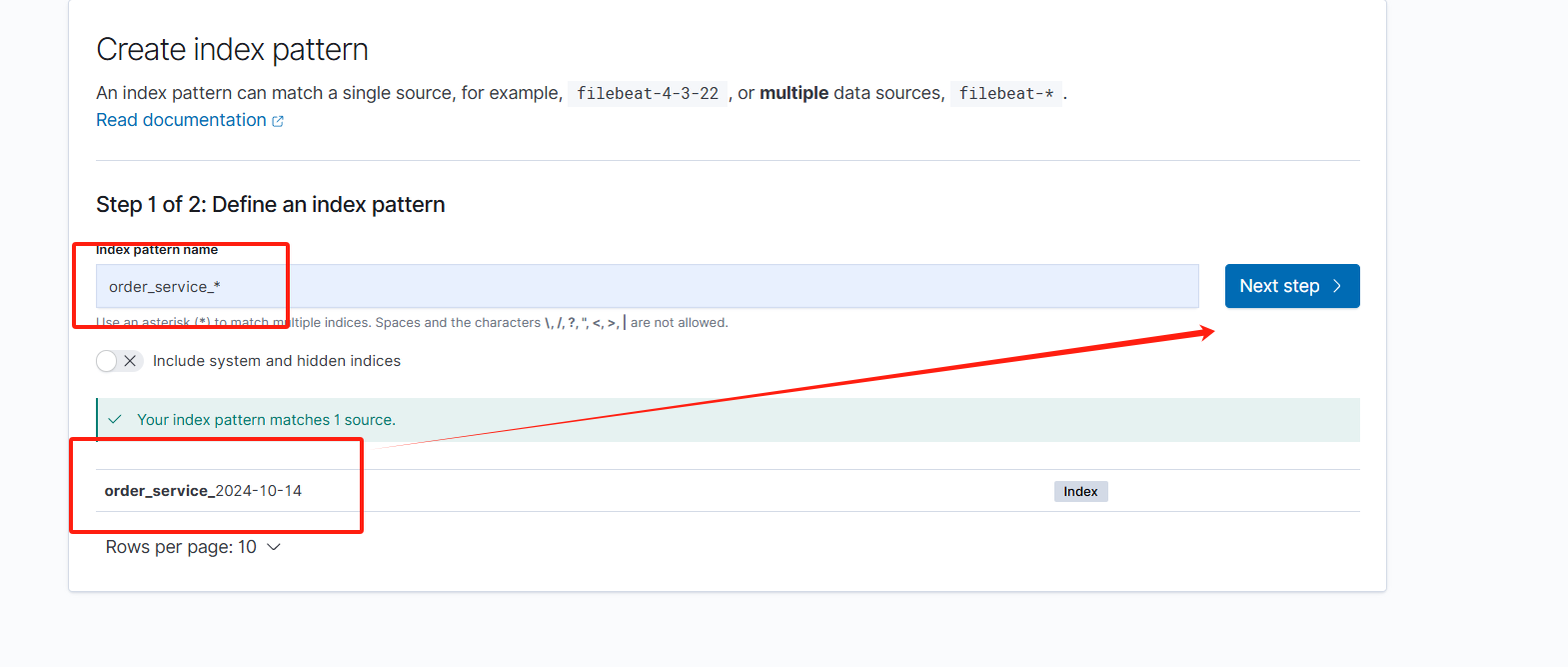
因为我们日志的索引后续跟上了当天的时间,这里会自动提示是否使用@timestamp作为筛选,当然是需要的。
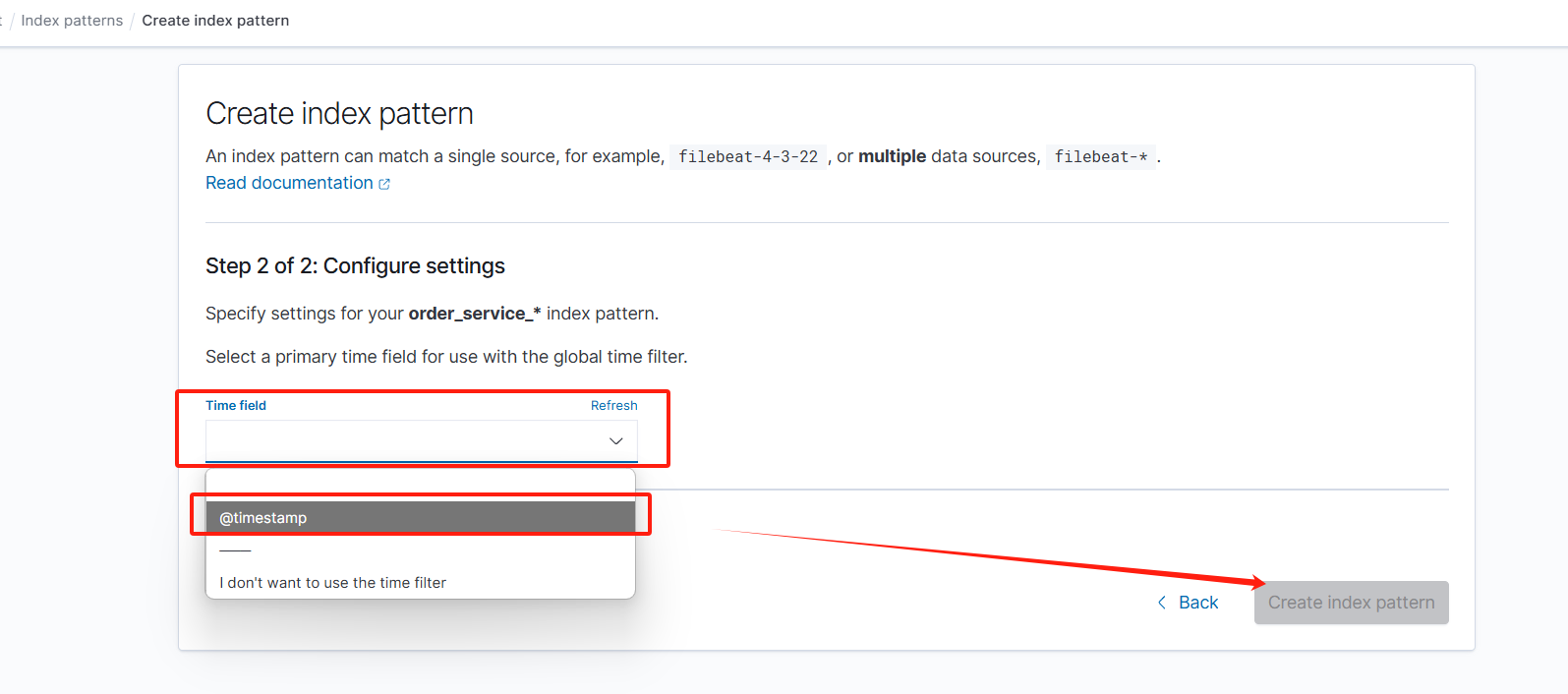
然后我们就成功创建出需要的 index_pattern 了
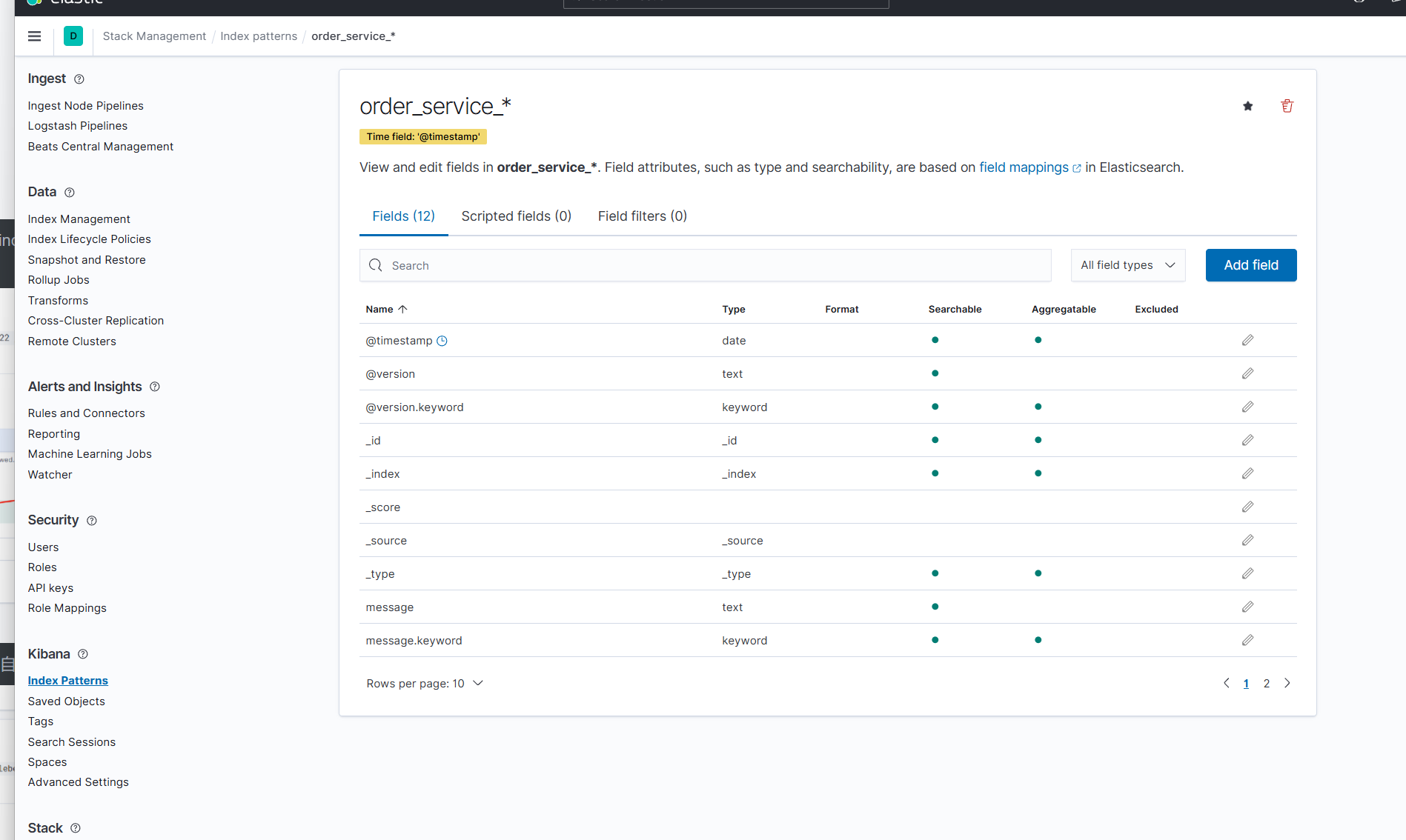
此时,我们就可以使用 kibana 的分析功能来根据日期来查看某一天的日志信息了

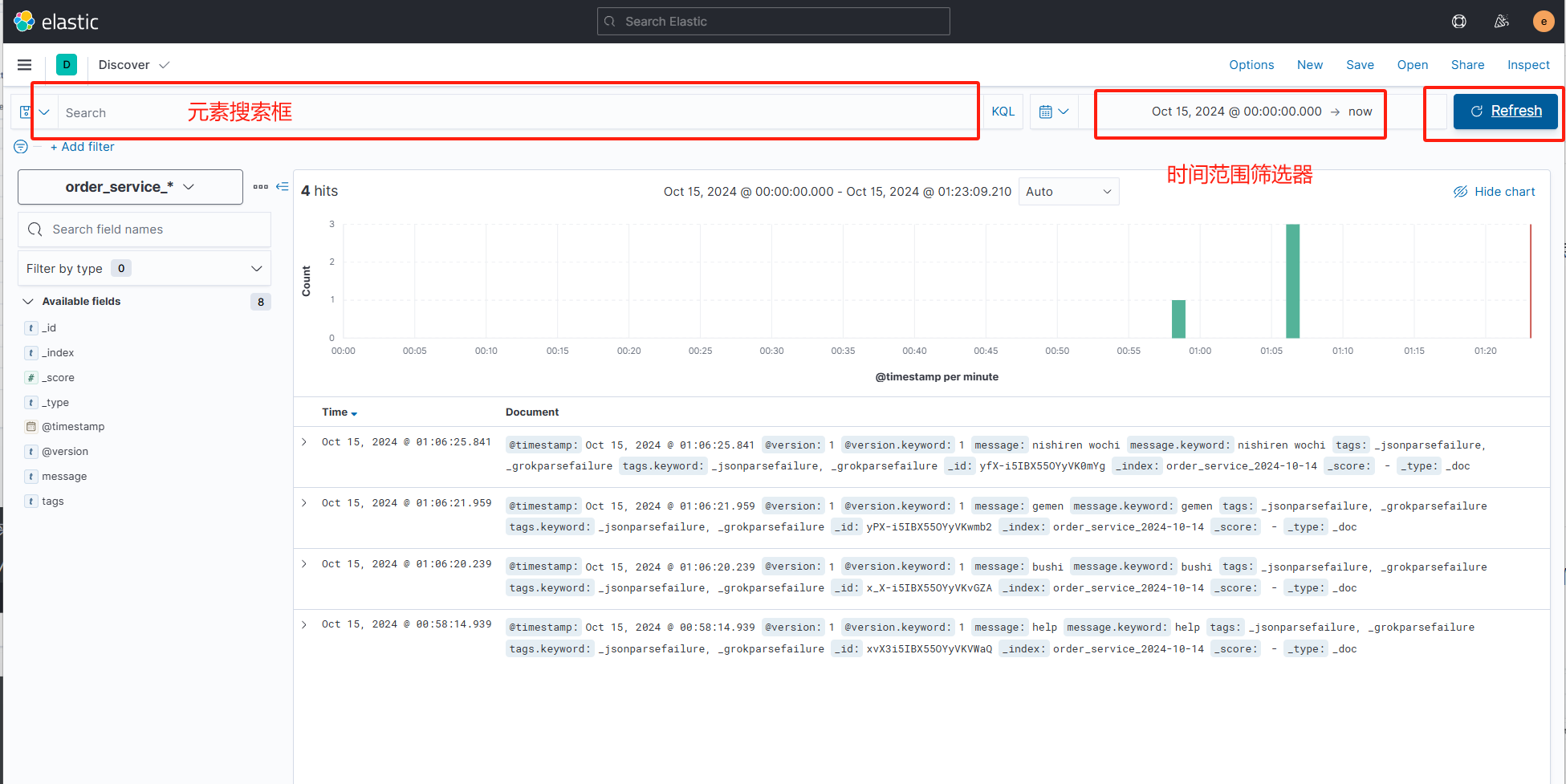
就此,我们就可以通过搜索框 + 时间范围筛选 点击refersh实现日志查询。最后补充一点,我们当然也可以在此筛选其他日志或者其他index_pattern的相关数据,创建出 index_pattern 后,只需要在此切换即可。