
ElasticSearch
基本概念
集群
Es集群的特点:多个ES服务器可以组成集群存储大量的数据,并提供相关的服务
- 高可用性 (服务可用性、数据可用性)
- 可扩展性 并发量提高、数据量增多的时候,可以增加节点来直接解决。
集群状态
ES将索引和集群的健康情况都做了以下三种状态的区别,每个索引或者集群都会有以下三个状态
健康情况:
- GREEN 处于健康情况,目前副本分片都在正常运行的状态
- Yellow 主分片 [主Data]都运行正常,但是部分的副本分片发生意外,存在发生故障之后数据丢失的可能。
(一旦出现主分片[Data]节点宕机的情况的话,这些数据一定会丢失) - Red 有部分的主分片没有正常的运行
如果集群之中的某个索引之中的副本分片出现宕机,那么这个索引本身喝集群都会进入到Yellow状态,但是其他索引的状态仍然会处于Green状态
以下先介绍一些比较常见和管理级别的基本查询,方便直接使用。
查看请求结果字段信息
# 在请求结果是表格结果返回的时候,我们往往可以通过 help 来帮助我们进行查询
GET /_cat/count?help
GET /_cat/master?help
GET /_cat/nodes?help
GET _cat/shards?help
GET /_cat/allocation?help
集群API查询
# 集群的健康状态
GET _cluster/health
# 集群状态
GET _cluster/state // 查看集群的状态
GET _cluster/stats?human&pretty // 查看es对集群情况做的统计信息
GET _cluster/settings?include_default=true // 查看集群的配置信息
# 节点信息请求格式查询
GET /_nodes/$[<node_id> / <metric> / {node_id/metric}]
# 主节点查询 API
GET _cat/master?v
# 集群节点查询 API
GET _cat/node
# 查询存在那几个索引
GET /_cat/indices
# 列出所有的节点信息
GET _nodes/$[_all、_local、_master、IP或者主机名字、节点ID或者名称、*、master: true/false、data:true/false、ingest:true/false、coordinating_only:true/false]
_all: 列出所有的节点信息
_local:列出所有的本地节点
_master:列出主节点
_IP或者主机的名字:列出指定的IP或者主机名字的节点
节点 ID 或者名称:列出指定 ID 或者名称的节点
*:IP、主机名字、节点 ID、名称都可以包括通配符
master:true/false:列出主节点 / 不列出主节点
data:true/false:列出数据节点 / 不列出数据节点
ingest:true/false:列出索引预处理节点 / 不列出索引预处理节点
coordinating_only:true/false:列出协调节点 / 不列出协调节点
sample: GET _nodes/master:true,data:true,ingest:true,coordinating:true/process
# 分片情况查询 API
GET _cat/shards // 所有分片信息
GET _cat/shards/${index}?v // 某个索引的分片信息
GET ${index}/_settings // 使用 json 结果查看某个索引的信息
GET _cat/indices/${index}?v // 使用表格形式查看某个索引的状态
GET _cluster/state/metadata // 集群状态 API,可以查看到所有索引的状态信息
查看某个索引的相关信息
查看某个索引的状态信息,都实际保存在 Index_Metadata 之中
GET /_cluster/state?filter_path=metadata.indices.${index}
GET /_cluster/state?filter_path=routing_table.indices.${index}
手动修改路由规则
配置路由规则之后,将会导致插入文档索引的数据会默认的配置到某个节点上,一般来说只会在比较特殊的场景下会使用该功能,利用某个节点的性能快速查找和索引文档。
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "${indexName}", "shard": ${shardNum},
"from_node": "${removeFromNodeN}", "to_node": "${removeToNodeM}"
}
},
{
"allocate_replica": {
"index": "${indexName}", "shard": ${shardNum},
"node": "${nodeN}"
}
}
]
}
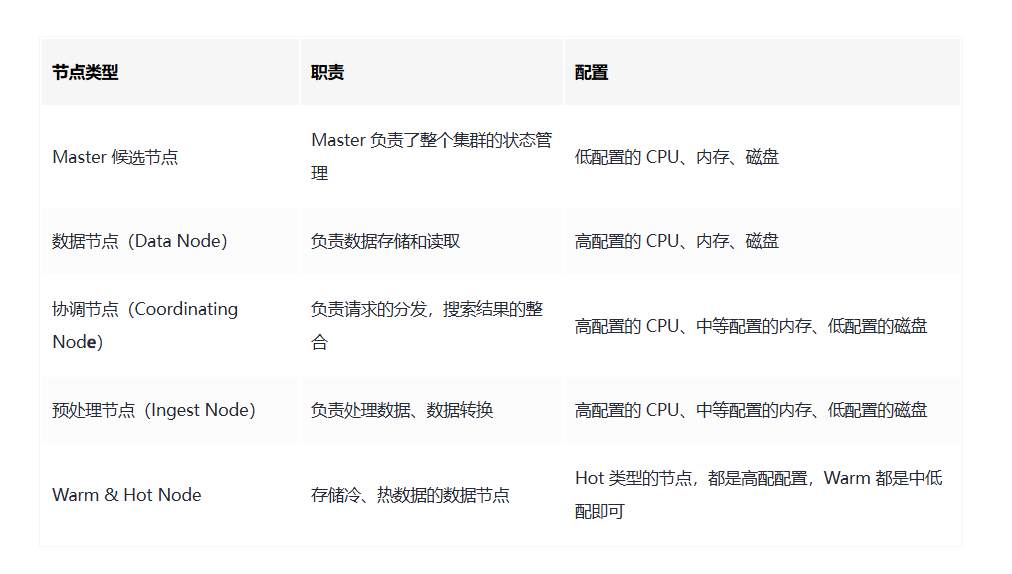
节点
ES节点:ES的每一个实际上的节点本质上其实就是一个Java的进程,本质上就是一个node.name之中的配置信息。我们通过添加或者减少node节点的方式来实现扩容又或者是减容的目的。
一般来说ES会包含以下几个节点类型:
- 主节点 Master (类似于zookeepr或者功能服务节点一样,充当数据更改、集群变更等一些关键工作)
- 数据节点 Data (负责保存数据,要扩充存储的时候往往需要使用这些节点)
- 协调节点 Coordinate (接受客户端的请求,并且讲请求路由到对应的节点上进行处理)
- 预处理节点 (该操作允许在写入文档之前先通过一些定义好的 processors 处理器和管道对数据进行转换,默认情况该节点的启动后就是预处理节点)
- 部落节点 (部落节点可以连接到不同的集群之中,并且支持将这些集群本身当做是一个单独的集群进行处理,但是按照elasticsearch官方的介绍,后续会在较新的版本之中淘汰掉该节点类型)
- Hot & Warm Node (不同硬件配置的Data Node,用来实现 Hot & Warm 架构的节点,有利于降低集群部署的成本,例如:在硬件比较好的机器之中部署Hot类型的数据节点,而在硬件资源一般的机器上部署Warm Node节点) [设计的思想跟分库分表的 冷热数据 拆分是一致的]
在ELK日志架构之中,会使用Hot记录最近的数据,而通过Warm记录最近N个月的数据,如果更早那么就通过Cold来记录更早之前的数据。
如何配置 elasticsearch 之中的不同的节点?
对于主节点、数据节点、预处理节点的配置都是类似的,但是针对Hot & Warm的配置其实是不一样的并不是在这里进行配置。在旧的版本之中和新的版本之中的配置是不一样的。(本质上是因为旧的版本不允许一个node可以拥有多种身份)
| Node | yaml setting name | yaml setting value |
|---|---|---|
| Master Node 主 | node.master | true |
| Data Node 数据 | node.data | true |
| Ingest Node 预处理 | node.ingest | true |
| Coordinating Node | 不需要配置 | 默认就是coordinationg (协调节点,负责将请求路由 到对应的节点进行处理,并且返回最终结果给客户端) |
而在新版的elasticsearch之中,该配置就得到了优化,更改为使用node.roles参数来指定,避免了麻烦的问题。
node.roles: [ master, data ] //设置节点为 master 候选节点和数据节点
node.roles本身是一个数组,node.roles本身可以 master / voting_only / data / data_content / data_hot / data_warm / data_cold / data_frozen / ingest / ml / remote_cluster_client / transform
| 节点名 | 节点详解 |
|---|---|
| master | master候选节点,elasticsearch主节点 从master选取 |
| voting_only | 参与 master 选举的节点,其只有投票权限, 当不会成为master |
| data | 保存文档数据的shard将分配到data节点之中保存 |
| data_content | 此角色的节点会处理用户创建的文档内容,如书本信息, 歌曲信息这类数据。可以用于CRUD、数据搜索和聚合等。 |
| data_hot | 该数据节点会根据数据写入ES的时间存储时序数据, 比如日志数据,data_hot节点对数据读写要求快速, 一般来说会通过SSD存储 |
| data_warm | 不会经常更新,但是依据是经常会被查询的数据 |
| data_cold | 很少再被读取的数据可以存储在 data_cold (只读) |
| data_frozen | 专门用于存储 partially mounted indices 数据节点 |
| ingest | 预处理数据的节点 |
| ml | 提供机器学习的功能,这类节点运行作业并处理机器学习API请求 |
| remote_cluster_client | 充当跨集群客户端并连接到其他集群 |
| transform | 运行 transforms 并处理 transform API 请求 |
| 不写 | 协调节点,负责接收客户端的请求,并将请求路由 到对应的节点进行处理,并且讲最终结果汇总到 一起返回 |
在节点的资源分配上,可以参考一下图表
设置节点属性
es之中可以通过以下命令设置节点的属性 (配置完毕后需要重启)
// 设置 node1 为 hot 节点
node.attr.box_type: hot
// 设置 node2 为 warm 节点
node.attr.box_type: warm
// 设置 node3 为 cold 节点
node.attr.box_type: cold
// 如果是docker-compose启动的集群,可以通过以下配置
environment:
- node.name=my_node1
- node.attr.box_type=hot
environment:
- node.name=my_node2
- node.attr.box_type=warm
environment:
- node.name=my_node3
- node.attr.box_type=cold
分片
该分片的概念其实很好理解,本质上跟Kafka本质上是相近的就是将文件拆分到不同的节点上进行存储,一般来说对应着分布式系统的设计思想和理念,我们就是需要将数据拆分为多个小块的数据,并且均匀的分配到各个机器上,然后就可以通过水平扩展机器的数量来对计算机系统的存储情况进行扩展。(通过分片的方式就可以分割巨大的索引,从而极大程度的提高系统的吞吐量)
副本
为了保证数据可靠性,ES对数据副本本身也做了主从类型备份分别是:主分片和副分片。在写入的过程之中,会先写入主分片,成功之后会通过多线程并发的方式写入到副分片之中,而在数据恢复的时候则是先利用主分片进行恢复。多个副本除了保证数据可靠性以外,还可以承担系统的读负载。(本质上很像Mysql的主从一致)
我们可以在Kibana之中使用以下的指令来配置分片数量和副本的数量
PUT books
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 2, # 定义了 2 个分片
"number_of_replicas": 2 # 定义了每个分片 2 个副分片
}
}
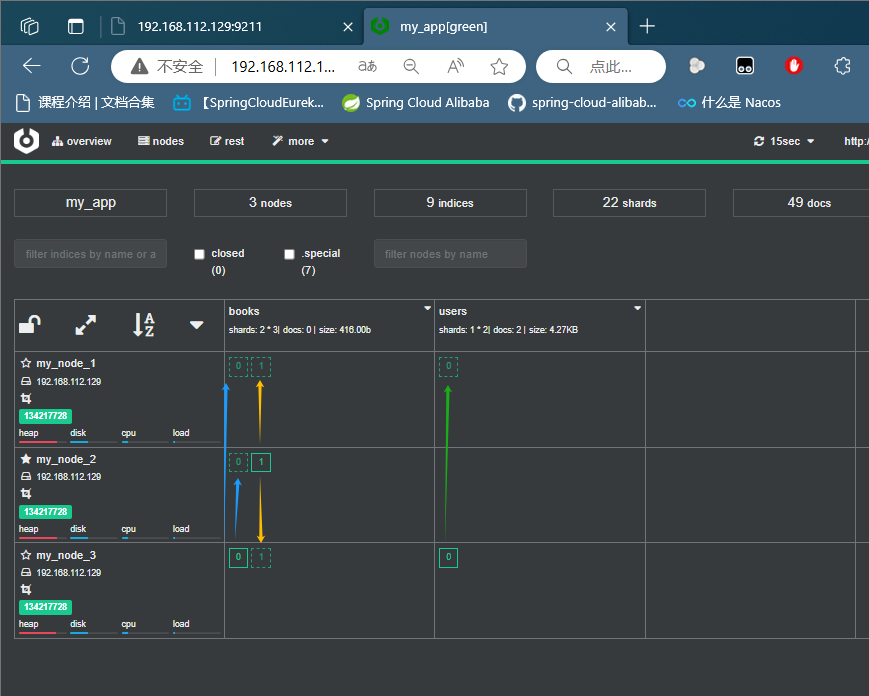
设置成功之后,就可以在Cerebro之中查看到以下数据,在首行之中会标记有 shards: 2 * 3 表示共有两个分片,每个分片有一个主分片和两个副分片,总共有三个副本。
示例1
PUT booksv2
{
"mappings": {
"properties": {
"book_id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "standard"
},
"name_completion": {
"type": "completion"
},
"author": {
"type": "keyword"
},
"price": {
"type": "double"
},
"date": {
"type": "date"
},
"seq_num": {
"type": "integer"
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
# 添加数据
POST booksv2/_doc/3
{
"book_id": "ab114516",
"name": "manba out",
"name_completion": "manba out",
"author": "kobe",
"price": 114.51,
"date": "2020-01-01",
"seq_num": 3
}
值得一提的是,虚线的方框其实指代的是,当前节点记录的是该索引的副分片,而实现的方框指代的就是该索引的主分片。(这里还有一个细节是需要注意的,在ealsticsearch之中其实是不允许出现副本的数量超过节点的数量的情况出现的,如果超过,那么集群的状态就会从GREEN变为YELLOW)
数据层面上的概念 & 操作
数据级别基本操作
POST /${index}/_open // 开启索引 & 关闭索引 (关闭索引后不能做读写操作,也不占用内存)
POST /${index}/_close
HEAD ${index} // 检查索引是否存在,存在则 返回200 OK,不存在则返回 not found
索引
**概括:**本质上索引本身跟关系型数据库表格之中表之中的数据。但不同的点在于ES存储的内容不仅仅只有值,往往还包含字段本身,并且ES存储的数据往往是JSON类型的数据。
索引是一类相似文档的集合,ES将数据存储在一个或者是多个Index之中,例如将用户数据存储在一个名为User的索引之中,而将订单数据存储在 Order Index 之中。一个索引有一个或者多个分片,而当然多个分片往往又会对应着N个副本,分别存储在不同的ES节点上。
| 机器\分区 | master-part | slave-part1 | slave-part2 |
|---|---|---|---|
| broker1 | 主1 | 副2 | 副3 |
| broker2 | 主3 | 副1 | 副2 |
| broker3 | 主2 | 副3 | 副1 |
需要注意的是索引的名字必须遵守以下的格式
- 只能是小写字母。
- 不能包含 \,/,*,?,",<,>,|,(空格),,,#等字符。
- 7.0 之后的版本不能再包含 : (冒号)字符了。
- 不能以 -,_,+ 开头。名字不能是 . 或者 ..。
- 不能长于 255 字节。需要注意的是某些字符是需要多个字节来表示的。
索引创建
普通索引构建模板
PUT ${indexName}
{
"settings": {
"number_of_shards": n, // 主分片数 【可选】
"number_of_replicas": m, // 副分片数 【可选】 总数量 = 主分片 * 副分片
"routing": "${route_value}", // 修改路由值 (一般不用该参数配置)
"index.lifecycle.name": "${udf_ilm_policy}", // 设置ILM索引生命周期【可选】
"index.lifecycle.rollover_alias": "${udf_auto_handle_alias}" // 设置生命周期完毕更新别名(热冷数据处理)【可选】
······
"analysis": {
"analyzer": { // [内置分词器使用]
"${built-in_analyzer}": { // 如果使用内置或者插件的 analyzer
// 设置分词器类型 (默认情况下会使用standard)
"type": "$[standard / simple / whitespace / stop / keyword / pattern / language /"
"fingerprint / custom(自组合) / snowball / icu_analyzer / phonetic]",
// 设置分词器的类型
"tokenizer": "$[standard / whitesapce / letter / lowercase / word_delimiter / pattern / uax_url_email / path_hierarchy / keyword / char_group / ik_smart / ik_max_word······]",
// 设置字符过滤器 (在执行分词之前处理【可选】)
"char_filter": [$["html_strip" / "mapping" / "pattern_replcas" / "icu_normalizer"]],
// 设置过滤器 (用于处理tokenizer的分词结果【可选】)
"filter": [$["lowercase" / "uppercase" / "stop" / "trim" / "stemmer" / "synonym" / "ascii_folding" / "snowball" / "length" / "truncate" / "pattern_replace", "pinyin" ······]]
}
}
}
},
"mapping": {
// 配置索引是否全局允许动态添加字段 【可选】
"dynamic": $[true / false / runtime / strict],
// 动态模板配置 (使字段可自动扩展、按照规则映射【可选】)
"dynamic_templates": [
{
{
"${template_name}": { // 设置模板的名字
"match_mapping_type": "string", // 匹配字段的类型
"${match}": "pattern", // 字段名称的匹配和不匹配模式
"${unmatch}": "pattern",
"${match_pattern}": "regex", // 匹配原则,一般是 regex
"${path_match}": "patch_pattern", // 字段路径的匹配和不匹配配置
"${path_ummatch}": "patch_pattern",
"mapping": { // 应用匹配字段的映射设置
"type": "keyword",
······
}
}
},
······
}
],
// 配置索引内部字段
"properties": {
// 普通数据类型
"${field}": {
"type": "$[keyword / text / integer / date ······]",
······ // 如果是 date ,可添加 format等类型规范 【可选】
// 如果是 keyword,可添加ignore_above 【可选】
// 设置字段是否被索引 【可选】
"index": $[true / false],
// 配置该字段是否可以动态扩展 【可选】
"dynamic": $[true / false],
// 设置字段的分词器 (默认standard) 【可选】
"analyzer": "$[analyzer-type / udf_analyzer]",
// 设置字段被搜索时的分词器 (不设置默认跟 analyzer 一样) 【可选】
"search-analyzer": "$[analyzer-type / udf_analyzer]"
// 设置特定值替换null的存储 (不影响实际值,只影响索引,类似于mapping) 【可选】
"null_value": "${NULL}",
// 设置copy_to 实际效果等同于 在n个字段中任一字段存在该都匹配 【可选】
"copy_to": "${other_field}",
// 设置 doc_values 是否生成,es针对keyword等会生成doc_values协助进行聚合、排序等操作
// 但会消耗大量存储空间, 需要注意关闭后无法再次打开 (text默认不开启)
// 一般来说,只有像 UUID 这种类型是百分百不需要 doc_values
"doc_values": $[true / false]
// 父子字段嵌套 模板
"$[fields / properties]": {
"${field}": {
"type": "$[keyword / text / integer / date ······]",
/* field common struct (same for root field) */
······ // 如果是 date ,可添加 format等类型规范 【可选】
// 如果是 keyword,可添加ignore_above 【可选】
},
······
}
},
// 对象嵌套对象
"${field}": {
"type": "nested",
"properties": {
"${son_field}": { "type": "${son_field_type}", ······ },
······
}
}
······
}
},
// 设置当前索引的别名【可选】
"aliases": {
"${udf_index_aliases}": {
// 设置别名的过滤器 【可选】
"filter": { "$[term / range]": {"${field}": "${value}" }},
// 是否写入到索引 【可选】
"is_write_index": $[true / false],
// 设置别名的路由 使用该参数配置值后,会同时指定索引 和 搜索的路由,如果数据量太大将会导致数据极度集中 【可选】
"routing": "${udf_routing_value}",
// 设置搜索的路由,使用该参数进行配置之后,会导致搜索请求指定到某个节点 (必须使用别名搜索)
"search_routing": "${udf_routing_value-for search}"
// 设置索引的路由,使用该参数会导致 (必须使用别名PUT / POST)
"index_routing": "${udf_routing_value-for store}"
}
}
}
由于想尽量让模板看起来简单一些,只保留了内置部分的配置,如果遇到或者想要自定义程度更高的模板,需要联系以下中提供的模板信息:
- 关于analysis的自定义模板 - 在分词器的时候详细介绍 分词器
- 关于settings之中更多的配置信息,可以参考官方文档 Index modules | Elasticsearch Guide 8.15 | Elastic
后配置mapping索引构建
需要注意的是在es之中,对索引的构建可以先创建索引,但是不写内部的 mapping :
# 先创建索引本身
PUT /${indexName}
# 补充 mapping 和 properties
PUT /${indexName}/_mapping
{
"properties": {
"${fieldName}": {
"type": "#{fieldType}"
},
······
}
}
// 但是需要注意的是,es不能对已经存在字段使用mapping来做修改,可以创建新字段
动态模板配置模板
所谓的动态模板的实现的类似效果是在构建索引的时候,不针对实际字段的数量和字段的类型做明文声明,这样的效果就是不需要规定死mapping-properties。但是这样也必然存在一些弊端:
- 性能的方面上:如果json之中的key经常有不完全一致,就会出现大量的字段的情况下,这样就会导致性能上es就会不断下降
- 映射的层面上:如果不在实际json插入或者说执行的时候,存在可能映射结果越来越复杂的可能性
- 一致性的层面上:如果不对插入的json进行校验等处理,可能会出现一些错误本身不应该存在的字段出现
当然es也支持针对插入的json提供了一些常见的内置的拦截处理配置:
-
dynamic: strict 可以阻止新字段的生成
也可以在动态模板索引有了一定数量级的数据之后,使用该参数限制新字段的出现
PUT ${index}/_mapping { "dynamic": "$[false / true / runtime / strict]" } -
ignore_malformed: true 来忽略不符合预期类型的数据
-
coerce:将字符串自动转换为数字类型 (Such: "123" -> 123)
当然在es之中还支持我们动态的对索引的mapping做动态模板的配置:
PUT /${index}
{
"mappings": {
${"dynamic": "$[true / false / null / strict]",} // 允许新增字段,有动态模板,大概率是false
"dynamic_templates": [
{
"${template_name}": { // 设置模板的名字
"match_mapping_type": "string", // 匹配字段的类型
"${match}": "pattern", // 字段名称的匹配和不匹配模式
"${unmatch}": "pattern",
"${match_pattern}": "regex", // 匹配原则,一般是 regex
"${path_match}": "patch_pattern", // 字段路径的匹配和不匹配配置
"${path_ummatch}": "patch_pattern",
"mapping": { // 应用匹配字段的映射设置
"type": "keyword",
······
}
}
}
······
],
"properties": {
// 显式定义的字段
"${fieldName}" : {
"type": "${fieldType}",
"ignore_malformed": "$[true / false]"
}
}
}
}
实际示例
PUT "${indexName}"
{
"mappings": {
"dynamic_templates": [
{
"ids_as_keywords": {
"match_mapping_type": "string",
"match": "*_id",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
索引删除
删除索引的实现方式很简单,一致都有在使用,他的示例如下:
# 删除一个索引
DELETE ${index}
收缩索引分片
一开始在创建索引的除了最常见的 mappings 的参数的配置以外,还有 settings 可以进行配置索引的分片情况和副本情况。下文会介绍在索引已经存在的情况下针对 mappings 修改处理,而接下来则介绍 settings 的修改处理。
需要注意的是,这里提到的所谓的索引分片的收缩,也不是直接针对原索引的修改,该行为本身也会创建一个新的索引。
减少分片数量 (但存在限制,收缩后的新索引的分片数量必然是原先的整数除值)、优化存储 (减少分片的行为可以降低)、提高查询效率 (更少的分片可以避免网络等影响效率的问题)、重新平衡集群 (均匀分配数据)
普通收缩示例
为了方便测试,这里先创建一个非常多分片的索引
PUT shards_index
{
"mappings": {
"properties": {
"id": {
"type": "integer"
}
}
},
"settings": {
"number_of_shards": 12, // 这里将该索引的主分片数量设置为了12个
"number_of_replicas": 2
}
}

需要注意的是,能够实现索引的分片处理的,索引在收缩之前必须满足以下的条件:
- 源索引本身必须是只读的 (不会突然有更多的数据插进来)
- 源索引所有的副本必须在同一个节点上,也就是单个es的服务上必须拥有该索引的所有数据 (其实一般就是单个服务,不能是集群状态)
- 源索引的状态必须是健康的状态的 (本质上还是要求数据在单个服务上是完好的)
其实上面的三个条件可以简述为:对索引的收缩必须在单个es服务上进行,并且不能有其他的动作再写入数据到索引之中。为了满足上面所述的三个要求,可以先执行以下的请求。
POST ${index}/_settings
{
"index.routing.allocation.require._name": "${nodeName}", // 将索引重新分配节点
"index.number_of_replicas": 0, // 保证只有单个服务有该索引数据
"index.blocks.write": true // 设置索引是否处于只读状态
}

收缩请求
POST ${index}/_shrink/${new_index_name}
{
"settings": {
"index.number_of_replicas": n, // 设置索引的副本数量
"index.number_of_shards": m, // 设置索引的分片数量
"index.routing.allocation.require._name": null, // 系统随机分配分片
"index.blocks.write": null // 设置索引是否处于只读状态
}
}
ILM高阶收缩
除了我们通过手动的方式实现索引收缩以外,还可以通过 ILM (配置索引自身的生命周期管理的功能方式实现自动控制索引的自动收缩功能)
以下是使用该方式的一个简单示例 (类似的ILM配置日志索引见于es用于ELK日志)
-
构建ILM policy
PUT _ilm/policy/udf_ilm_policy { "policy": { "phases": { "hot": { "actions": {} }, "warm": { "min_age": "30d", "actions": { "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 1 } } } } } } -
构建一个使用上面 ILM Policy 的索引模板 (索引模板的构建会在后续详细介绍)
PUT _index_template/udf_index_template { "index_patterns": ["logs-*"], "template": { "settings": { "number_of_shards": n, "number_of_replicas": m, "index.lifecycle.name": "udf_ilm_policy", "index.lifecycle.rollover_alias": "logs" } } } -
创建首个索引
PUT logs-000001 { "aliases": { "logs": { "is_write_index": true } } }
该ILM收缩效果会让索引达到30天之后,将索引本身收缩到单个分片之中,一般用于 hot 数据到 warm 数据的转换
索引别名
在实际使用的时候,很有可能会因为时间的变化原先的索引已经不能很好的支持我们的业务需求,在这个情况下,就需要更改索引(主要其实就是修改索引的 mapping ),而es考虑到这个问题提供了索引别名的功能。(从行为上来看,基本等同于映射 直接将原先的业务映射到存储上的新索引上)
所有的索引别名其实就是将新的别名指向原先的索引,并最终将旧索引的数据迁移到新的索引之中,从而实现旧索引直接迁移到新索引之中使用的效果。
值得一提的是,所谓的索引别名单纯就相当于索引的另外有一个名字,索引本身可以有多个的别名,而不同的索引也可以有相同的别名。
别名基本操作模板
// 构建别名模板
POST /_aliases
{
"action": [
{ "add": { "index": "${indexName}", "alias": "${aliasName}" } }
]
}
// 删除别名模板
POST /_aliases
{
"action": [
{ "remove": { "index": "${indexName}", "alias": "${aliasName}" } }
]
}
// 别名重命名操作
POST /_aliases
{
"action": [
{ "remove": { "index": "${indexName}", "alias": "${aliasName}" } },
{ "add": { "index": "${indexName}", "alias": "${aliasName}" } }
]
}
// 单个别名关联多个索引
POST /_aliases
{
"actions": [
{ "add": { "indices": ["${indexName1}", "${indexName2}"], "alias": "aliasName1"}}
]
}
实际上我们在使用 ILM 自动化生成新索引 又或者是手动创建类似索引的情况下,往往还需要针对多个这些索引做查询、插入等操作 (当然插入的时候,必须保证必须是只有一个索引目前处于 is_write_index 状态)
我们可以通过使用别名来插入日志数据
POST ${alias_name}/_doc
{
"${field}": "${field_value}"
}
当然也可以通过别名来查询我们的索引
GET ${alias_name}/_search
{
"query": {
"match_all": {}
}
}
GET ${alias_name}/_search
{
"query": {
"range": {
"@timestamp": {
"gte": "2023-01-01",
"lte": "2023-12-31"
}
}
}
}
GET ${alias_name}/_search
{
"query": {
"match": {
"log_msg": "error"
}
}
}
但其实需要注意的是,其实我们也可以通过 通配符的方式 实现多索引查询的效果
GET book*/_search
{
"query": {
"match_all": {}
}
}
索引模板
index templates,在es之中索引模板本身的工作是为了实现索引的自动化的创建本质上其实等同于实现在创建时通过预定义的设置和映射实现索引的创建。
在索引模板之中,可以预先对以下的内容做设置:
- 字段的映射:预先设置字段类型、分析器、动态mapping等
- 模式匹配:通过通配符匹配索引名称,并自动引用模板
- 优先级的配置:如果有多个模板都匹配使用,还可以依靠优先级决定最主动采用哪一个模板来创建索引
- 索引的分片设置:可以事先配置分片树、副本数、刷新间隔时间等
该模板配置一般比较常见于日志处理上,类似的配置创建索引
常见模板
PUT /_index_template/${index_template_name}
{
"index_patterns": ["${regex}"], // 使用正则表达式来控制什么情况的索引构建会使用该模板
${"priority": n,} // 该模板的优先级
"template": { // 索引模板的主体
"settings": {
${"order": n,} //
${"number_of_shards": m,} // 使用该模板的默认分片数量
${"number_of_replicas": j, } // 使用该模板的默认副本数量
"analysis": {
/* 这个部分其实完全等同于上文索引模板 */
"analyzer": {
"${udf_analyzer}": {
"type": "custom",
"tokenizer": "$[standard ······]",
"filter": $["lowercase ······"]
}
}
}
/* 日志类型参数设置 */
// ${ "index.refresh_interval": "ns" } // 设置刷新间隔 n 秒
/* 时间序列数据索引 (类似于传感器 / 股票等时间变动数据会变动的数据) */
// ${ "index.lifecycle.name": "timeseries_policy", } // 指明当前索引使用的 ILM Policy (一旦配置的 ilm.policy 就一定要 routng 和 rollover_alias 不然会有不可预测的结果)
// ${ "index.lifecycle.rollover_alias": "", } //
// ${ "index.routing.allocation.include.box_type": "hot", } // 指明新建的索引都分配在hot节点上
/* 存储指标数据 (用于记录系统监控信息) */
// ${ "index.mapping.total_fields.limit": 2000, } // 索引内部可以定义的字段最大数量
// ${ "index.refresh_interval": "30s" } // 索引中嵌套字段的最大数量
},
"mappings": {
"properties": {
/* 这个部分其实完全等同于上文索引模板 */
"${field}": {
"type": "${fieldType}"
},
"${@timestamp}": { // 如果是timestamp,一般会使用 @timestamp 代替 timestamp
// [@符号排名靠前、@timestamp可以避免与es自带的冲突]
"type": "date",
"format": "${strict_date_optional_time||epoch_millis}" // 设置时间戳格式
}
······
},
${"date_detection": $[true / false],} // 是否默认自动检测为 date 类型数据,并自动转换
${"numeric_detection": $[true / false],} // 是否自动检测为 number 类型,并自动转换
},
"aliases": {
"logs_current": {} // 设置当前索引的别名
},
// 使用压缩模板设置压缩效果
${"composed_of": ["udf_compression_template"]}
}
}
索引生命周期 (ILM)
在当前文档之中,对索引构建期间,又或者在索引的行为规定的期间,有一些内容会提到使用ILM_POLICY,在索引的一定时期自动的做某些操作 (自动化的索引管理功能) 。这里补充介绍一下,索引的ILM到底是什么。
阶段 (Phrase)
ES在概念上,将一个索引的生命周期区分为以下多个阶段:
HOT -> Warm -> Cold -> Frozen -> Delete
**HOT:**索引处于 写入、查询的活跃期间,这时一般采用最快的存储设备
**WARM:**索引处于 写入很少、但是查询还比较频繁的情况,一般来说采用性能稍微较差,但是容量很大的存储设备
**COLD:**很少被查询的情况,一般来说,直接采用机械硬盘这种存储量很大,但是性能也相对应差的设备
**DELETE:**索引数据用不上了,一般来说,会将这种级别的索引直接删除
行为 (Action)
- Set Priority:设置Index的处理优先级,如果出现节点宕机等情况恢复时,将会依靠该配置项来按照优先级逐个恢复索引
- Rollover:设置该Action,可以在索引数据发展到某个规模 / 时间点的时候,自动创建切换到新索引继续使用 (非常常见于 ELK 记录日志的处理的索引中)
- Migrate:自动化的索引迁移,实际上就是将索引的节点组做迁移 (一般用在索引从Hot阶段转移到Warm或者Warm转到Cold等场景下,也比较常见于 ELK 记录日志的处理索引之中)
- Searchable Snapshot:自动化的索引生成快照,一般用于生成定时检查的场景等。
- Wait For Snapshot:在删除索引之前,等待ILM协议执行完毕,一般用于在潜在对数据产生危险影响行为之前的保护工作 (删除前提前生成快照、备份等)
- Allocate:提供自动化的索引设置更新,可以重新分配索引分片的存储节点和更改分片的副本数量等。
- Read-Only:设置之后,索引会变为只读状态
- Force Merge:强制合并索引,可以最大限度的减少索引占用的Segment文件的数量 (等同于加强了存储期间的 Merge 行为)
- Shrink:跟下文的Shrink是一样的,其实就是设置自动化的索引收缩
- Freeze:自动化的冻结索引,减少其占用的存储空间 (一般用在索引往生命周期后期转变的阶段时)
- Delete:自动化删除索引
- Unfollow:设置该Action之后,可以使得索引本身从异地多机房的官方CCR架构 / 主从状态下的索引 状态下的转变为普通索引,随后我们就可以针对该索引做收缩等会影响索引数据的操作 (ES禁止主从 / 多机房的修改行为避免级联风暴)
在上文索引创建之中其实提供了一个模板,其中就有使用到Rollover的使用示例,因为这个部分其实是相当复杂的,这里扩展的介绍会在另外一个文档之中详细说明。
策略 (Policy)
上文提到的阶段和阶段期间可以使用的行为,但是需要注意的是,上文仅仅介绍了在索引的某个阶段可以有什么行为,但是并不能完整的组成一个完整的索引生命周期配置。而如果想要做到针对索引的自动化配置级别的设置,那就需要配置策略。 (其实这个之前的文档也有介绍过,有需要可以跳转 策略声明
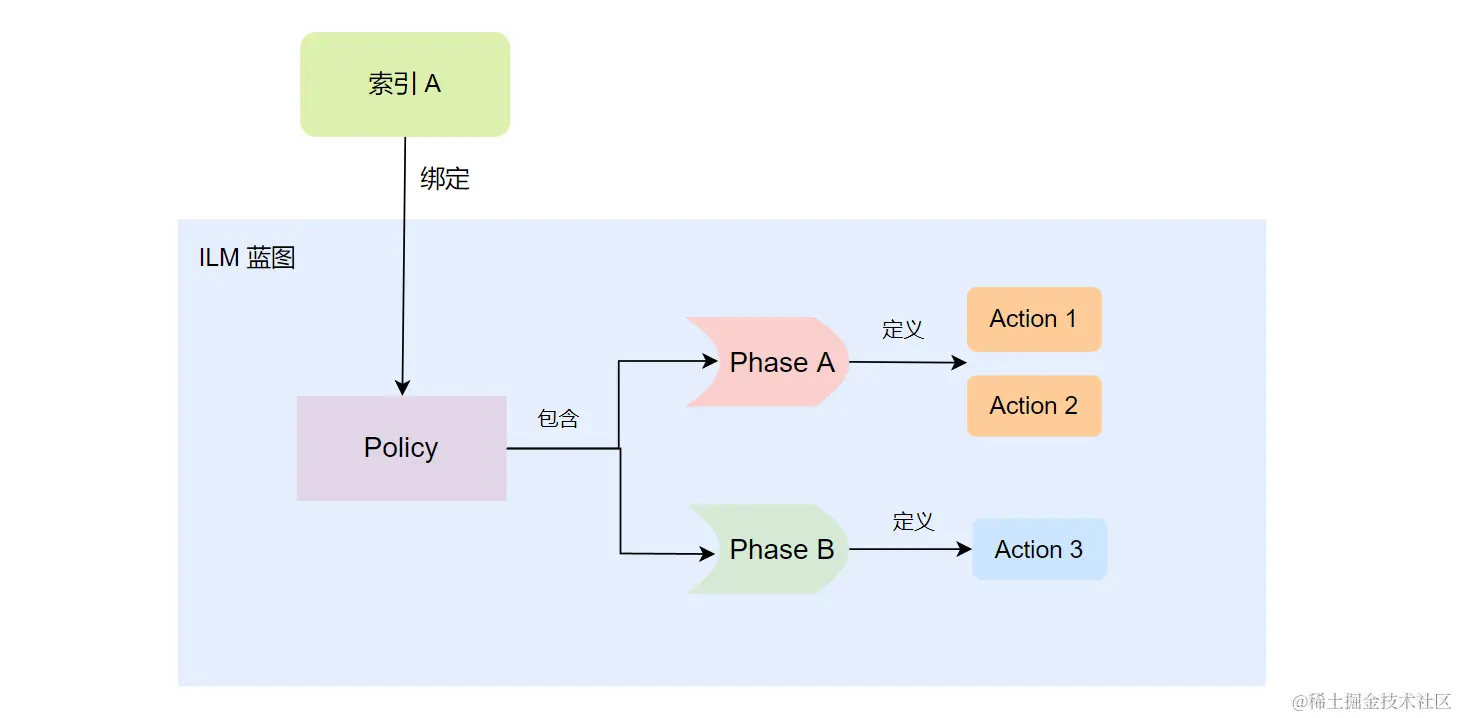
以下是一个简单的声明策略的模板
// 定义一个策略
PUT _ilm/policy/${policyName}
{
"policy": {
"phases": {
"hot": {
"min_age": "0s", // 多久之后进入到该阶段
"actions": {
${built-in action}: { /* built-in action struct */ }
},
"set_priority": {
"priority": n // 设置 hot 阶段的索引的优先级
}
},
"warm": { /* same as hot */ },
"cold": { /* same as hot */ },
"delete": { /* same as hot */ }
}
}
}
// 查看 Policy 的信息
GET _ilm/policy/${index}
// 删除 policy 的信息
DELETE _ilm/policy/${index}
// 声明一个 hot阶段 大小超过5GB、年龄超过30天 就会创建新索引、且设置 Warm 阶段会将索引副本数量设置为 1
PUT _ilm/policy/my_index
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB",
"max_age": "30d"
}
}
},
"warm": {
"action": {
"migrate": {},
"allocate": {
"number_of_replicas": 1
}
}
}
}
}
}
ILM绑定到索引
// 将 ilm 绑定到 某个索引上,方式1 & 方式2
PUT ${index}
{
"${mappings}": { /* mappings struct */ },
"settings": {
"index.lifecycle.name": "${udf_ilm}"
}
}
PUT ${index}/_settings
{
"settings": {
"index.lifecycle.name": "${udf_ilm}"
}
}
ILM绑定到索引模板
PUT _template/${template_name}
{
/* template struct */
"settings": {
"index": {
"lifecycle": {
"name": "${udf_ilm_policy}",
"rollover_alias": "${create index alias}"
}
},
/* other settings struct */
}
}
Mapping
概括:本质上Mapping大致上等同于关系型数据库表格之中的表结构,但是有一点不同的在于ES的Mappring是不可以被修改的。(可以在声明索引时声明,又或者在后续补充,但是不可定义后又再次修改)
Mapping定义了索引之中的文档会有哪些字段和这些字段的类型,类似于数据库之中的表结构的定义,Mapping有两个作用:1. 定义了索引之中各个字段的名字和类型 2. 定义了各个字段、倒排索引的相关设置,比如使用了什么分词器等等。但是需要注意的是Mapping一旦被定义,那么已经定义了的字段是不能被修改的。
在Mapping之中,我们可以设置一些参数来来决定es针对这些参数的一些行为,比较常见有以下的参数:
-
index: 配置字段本身是否构建倒排索引 (不能用于搜索,但是可以存储) [true / false -field级别]
-
index_options: 控制将哪些信息添加到方向索引之中并进行搜索和突出显示,一般来说只针对text有用。
-
index_phrases:提升 exact_value 的查询速度,但是往往需要消耗更多的磁盘空间。
-
index_prefixes配置前缀索引
-
enable:配置是否针对所有的字段构建倒排索引,如果配置为false,本质上是作用于全局的设置 [true/false - mapping级别]
-
ignore_abvoe:在建立倒排索引的时候,忽略超过一定长度的字符串 [true/false - mapping级别]
-
ignore_malformed:忽略类型的错误 [true/false - mapping级别]
-
analyzer:指定字段的分析器 [character filter / tokenizer / Token filters - mapping级别]
-
boost:指定在查询的时候该字段的相关评分权重 【1-n 整数 - mapping级别 等同于query field^n的效果】
-
coerce:指定是否允许强制类型转换,但数据类型转换可能会导致数据丢失精度问题 (一般只有在原始数据存在错误类型问题的时候才会使用) [true / false -field级别]
-
copy_to:该参数允许将多个字段的值复制到组字段之中,然后可以将其作为单个字段进行查询。 [true / false -field级别]
-
doc_values:默认就是 true ,为了提升排序和聚合的效率,默认true,在确定不需要对字段进行排序和聚合的情况下,也不需要通过脚本访问字段的值,那么我们就可以使用doc值去节省磁盘空间,对于 text 类型的字段,该配置是无效的。
-
dynamic: 控制是否可以动态添加新的字段 [true / false / strict -mapping级别]
- true:但该值为true的时候,允许一个文档存在 mapping 之中没有声明的字段和类型存在
- false:新检查到的字段会被忽略,这些字段本身不会被索引到,因此不会被搜索出来。但是仍然会出现在 _srouce 返回的内容之中,这些字段本身不会添加到映射当中,必须修改 index 的包含的字段才会生效。
- strict:如果检测新字段之中,则会引发异常并拒绝文档 更新或者是新增 。必须将新字段显式添加到映射
-
eager_global_ordinals:用于聚合的字段上,消耗内存记录全局序号,优化聚合性能,但不适合用于 Frozen indices: [ true / false - fields 级别 ]
-
Frozen indices(冻结索引):有些索引使用率很高,会被保存在内存之中,有些使用率特别低,宁愿在使用的时候重新创建索引,在使用完毕后丢弃数据,Frozen indices 的数据命中率比较小,并不适合高搜索负载,数据不会被保存在内存之中,堆空间占用会比普通索引少很多。 (也就是说在冷数据的 node 之中最好不要使用该参数)
影响效果:
优点:
- 开启该值之后就会加速 聚合速度,但是会增加索引刷新时间。
- 开启该配置之后可以实现动态更新,不需要重建索引。
- 使用该功能可以帮助监控集群内存的使用情况。
缺点:
- 使用该配置会导致堆内存增加,因为全局序号 (elasticsearch优化keyword聚合的优化机制) 刷新的时候会将其加载到内存之中
-
总结:eager_global_ordinals 在针对keywords类型的,存在经常需要聚合操作的字段的时候,我们可以使用该配置提高性能,但是需要注意的一点是,使用该配置的时候,会增加内存的占比。
-
-
fielddata:查询内存数据结构,在首次用当前字段聚合、排序或者脚本之中使用的时候,需要使用fields创建倒排索引放到堆之中 (需要注意的是fielddata实际使用的时候,es还会像 keyword 做聚合一样,尝试使用 global ordinals 进行优化)
-
null_value:为null值设置默认的取值
-
norms:配置是否禁用评分机制
-
store:设置字段是否仅用于查询
一定要修改mappings
如果我就是需要修改mappings有什么办法?es还是提供了一个API满足了我们的需求的,这个API就是 Reindex API,但其实这个也不是在原先索引的基础上做修改,而是新建一个索引,然后做迁移。(本质上等同于操作系统之中的 copy 行为,这点和收缩索引的行为是不一样的,收缩索引一般情况下,不会大量增加存储占用,但从结果上来看,reindex和收缩索引都会创建出新的索引)
假设目前有两个已经存在的索引,第一个是原先已经存在的索引 (也就是旧的索引本身 index1);第二个则是新建的索引本身 (index2)。那么我们就可以通过Reindex来进行处理,以下是两种情况的示例模板。
简化的Reindex
一般来说,如果不需要实现字段名字的修改,只是单纯的对字段的类型、新增字段的数量的情况下,可以直接通过简化的reindex实现修改。
# 如果数据量不大,那么可以通过以下模板来实现修改
POST _reindex
{
"source": { "index": "${source_indexName}" },
"dest": { "index": "${dest_indexName}" }
}
# 如果有着大量的数据的话,es的请求大概率就会出现超时的问题,因此,我们可以将其设置为后台处理 ·?wait_for_completion=false·
POST _reindex?wait_for_completion=false
{
"source": { "index": "${source_indexName}" },
"dest": { "index": "${dest_indexName}" }
}
# 在成功调用之后,最终的执行效果,可以通过
GET /_task/taskSeq 获得
更复杂的Reindex API
当两个索引的字段并不完全一样的时候,我们可以通过script脚本的方式帮助我们实现修改。
POST _reindex
{
"source": { "index": "oldindex" }, // 原索引
"dest": { "index": "reindex" }, // 目标索引
"script": {
"source": """
ctx._source.${destFieldName1} = ctx._source.remove("${sourceField1}"); // 转换规则
ctx._source.${destFieldName2} = ctx._source.remove("${sourceField2}");
ctx._source.${destFieldName3} = ctx._source.remove("${sourceField3}");
ctx._source.remove("date") // 去掉不需要的字段 (如果原先有这里不做处理)
"""
}
}
通过这个方式就可以通过利用脚本语言编写自定义脚本的方式来帮助我们实现字段名字 + 类型 + 增加字段的工作,也可以将不需要的字段去掉。
文档
**概括:**本质上文档对应着关系型数据库之中的行单位,也就是在ES之中的一个文档对应着关系型数据库之中的一条数据。
实际上我们通过post往ES之中插入的每一条数据本身都是一个文档,这一行为其实也跟往关系型数据库之中插入一行新的数据是类似的,需要注意的是我们搜索行为本身也是以文档作为单位的,所以在ES之中文档才是主要的数据单位。
# such as
POST books/_doc/1 # 从左到右分别是 index: books type: _doc id: 1
{
"book_id": "1", # 字段book_id为1
"name": "elasticsearch 从入门到放弃学习" # 字段name为 ······
}
而查询起来也很简单
POST books/_search # 从左到右动作是 index: books type:_search 表明此次是查询操作
{
"query": { # 表明是查询
"match_phrase": { # 标识精准匹配一个词语或者是一个字段的值
# 与之对应的是 match_phrase_prefix (一般用于字符串) 这里最好是用 term
"book_id": 1
}
}
}
结果 (result)
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"book_id" : "1",
"name" : "elasticsearch 从入门到放弃学习"
}
}
]
}
}
字段
每个文档都有一个或者多个字段,例如books索引指定了书本的记录有 book_id 和 name 两个字段,其实就是JSON的key - value。当然需要注意的一点是每个字段都会有指定的类型,在elasticsearch之中常见的类型有:keyword (适合简短而且有一定结构的字符串,如短信、邮件的内容等)、text、数字类型(Integer、long、float、double等)
词项
将全文本的内容进行分词之后获得的词语就是词项。而负责将全文本拆分为词项的就是分词器来负责分词(本质是依靠多种语法来实现的分词,另外还会将分词进行大小写转换)
分词器 analysis
es之中支持许多分词器,针对英语 / 中文 都有许多分词器实现分词效果,英语分词器就包含 stadard / character filter / tokenizer / Token filters 等。而对于中文分词器来说有类似于拼音分词器一样的,针对该实现存在 github 针对 es 的拼音分词器,可以自动实现汉字的拼音分词搜索效果。
不同的分词器进行分词最终获得的分词效果是不同的。因此如果在某些情况下出现正确的内容搜索失败有可能是分词器导致的。
在有的场景下,我们可以自定义分词器来实现我们的分词功能,保证我们需要的分词效果和查询效果。
在整个analysis之中往往包含一下的可配置项:
- analyzer:分词器本体配置
- analyzer名字
- type:分词器的类型
- tokenizer:分词器本身
- char_filter:针对未分词的原文本做处理 (character filter)
- filter:针对分词结果的过滤处理器 (token filter)
- analyzer名字
在es的概念上,分词器的主要组成是三个部分: 1. character filter 2. tokenizer 3. token filter,他们针对字符的处理顺序也遵守这个顺序实现处理。
es内置提供了一些比较很常见的分词器:standard、simple、whitespace、stop、keyword、pattern、language、fingerprint (直接设置 analyzer.type即可使用)。当然这些往往还是不能满足我们的需求的,在需要自定义的情况下,analyzer的type还支持了custom (允许我们自己组合tokenizer、char_filter、filter等构成分词器)
- Standard Analyzer:默认的分词器,使用Unicode进行分词,并会将结果转为小写字母。(适合处理英文类型字符)
- Simple Analyzer:按照非字母切分,并且转为小写
- Stop Analyzer:在Simple Analyzer的基础上做了增强,去掉了停用词(a、an、and、are等)
- Whitespace Analyzer : 使用空格对文本进行切分,并不进行小写转换。
- Patter n Analyzer : 使用正则表达式切分,默认使用 \W+ (非字符分隔)。支持小写转换和停用词删除。
- Keyword Analyzer : 不进行分词。
- Language Analyzer : 提供了多种常见语言的分词器。如 Irish、Italian、Latvian 等。
- Customer Analyzer:自定义分词器。
analyzer-type
如果有需要了解内置的分词器,可以参考官方的介绍
Built-in analyzer reference | Elasticsearch Guide 8.15 | Elastic
tokenizer-type
分词器本身也有多种类型可以选择,一般常见的有:[standard / whitesapce / letter / lowercase / word_delimiter / pattern / edge_ngram / char_group / ik_smart / ik_max_word]。如果有需要,也可以参考官方文档之中的介绍
Tokenizer reference | Elasticsearch Guide 8.15 | Elastic
另外在构建索引时,常常会有自定义分词器的要求,以下提供一个自定义分词器的模板
自定义分词器模板
PUT ${indexName}
{
"settings": {
······
"analysis": { // analyzer、[tokenizer、char_filter、filter 服务于analyzer]
"analyzer": {
"${udf_custom_analyzer}": { // 如果要完全自定义 analyzer
"type": "custom",
"tokenizer": "${udf_tokenizer} / ······ / 其他内置的tokenizer",
"char_filter": ["[${udf_char_filter}", ······ / "其他内置的字符过滤器]"],
"filter": [$["${udf_filter}", ······ / "其他内置的过滤器"]],
"tokenizer": {
"${udf_tokenizer}": {
"type": "$[pattern / simple_pattern / classic / ngram / path_hierarchy / edge_ngram / char_group / keyword / whitespace ······]",
// if type is pattern / simple_pattern
// "pattern": "${regex}"
// if type is char_group (自定义在字符切割)
// "tokenize_on_chars": [${char}, ······]
······
}
},
"char_filter": { // 自定义字符过滤器
"${udf_char_filter}": {
"type": "$[html_strip / mapping / pattern_replcas / icu_normalizer]",
// if type is html_strip
// "escaped_tags": ["${html tag such as span}"]
// if type is mapping
// "mappings": [ "${char} => ${char}", ······]
// if type is pattern_replcas
// "pattern": "${regex}",
// "replacement": "${replace_str}"
// if type is icu_normalizer (语汇单元过滤器)
// "name": "$[nfc / nfkc ······]",
// "mode": "decompose"
······
}
},
"filter": { // 自定义过滤器
"${udf_filter}": {
"type": "same for built-in filter type",
${udf_filter_body} // 无法提供确定模板,太多了
······
}
}
}
}
},
······
}
}
分词器功能测试
如果想要知道自身配置的分词器针对某段字符串进行分词的效果如何。可以通过使用 _analyzer API指定Analyzer来进行测试。
GET _analyze
{
"analyzer": "${build-in analyzer}",
"text": "${udf_string}"
}
// 如果需要使用在某个index声明的时候写的自定义分词器
GET ${index}/_analyze
{
"analyzer": "${udf_analyzer}",
"text": "${udf_string}"
}
// 如果想要对自己还没实际构建的索引进行测试 (只支持内置的)
GET _analyze
{
"tokenizer": "${built-in analyzer}",
"filter": [$["lowercase"······]],
"text": "${udf_text}"
}
系统级别上的概念
近实时系统
本质上ES并不是真正意义上的实时系统,他每一次查询都其实是需要大概 1 s 后才会被查询到。ES每秒都会把缓存之中的数据写入到Segment文件之中,只有写入到Segment中才能被检索到。然后根据某些规则写入到盘之中,并且合并到Segment。所以需要注意的是,不能再写入数据之中,立刻进行查询,否则就可能会破坏掉事务(查不到写入的数据等)
Lucene和ES的关系
Lucene是一个用在全文检索的开源项目之中的,ES在搜索的底层其实就是在使用Lucene,并加上了分布式系统的服务效果。
ES的数据结构
字符串类型
- keyword:适合简短而且有一定结构的字符串,如某种编号、短信、邮件的内容等
- text:等同于常见的较长的String类型字符串
数字类型
- byte:类比java
- short:类比java
- integer:最简单的整型类型的数据
- long:类比 java 中 Long
- half_float:半个float大
- float:类比 java 中 Float
- scaled_float:更加精确的float
- double:类比java 中 Double
日期类型
- date:类比java
- data_nanos:在日期的基础上加上 nano secods 也就是毫秒、纳秒级别
布尔类型
- boolean:其实是虚假的boolean在es内部存储的其实还是数字 0 - 1
对象类型(嵌套类型)
从数据存储的角度来看,最终会改为扁平化存储,类似于OSS
需要注意的一点是,nested本质上其实是将数据进行冗余了,比如内部嵌套的子字段很有可能,其实不符合数据库的第一范式,也就是拆到最小单位的要求,因此如果需要对子字段进行修改,就需要对所有的字段进行处理 ====> 因此 nested 类型仅仅适合经常查询,但是基本不修改的场景
嵌套类型声明方式
// 对象嵌套对象
"${field}": {
"type": "nested",
"properties": {
"${son_field}": { "type": "${son_field_type}", ······ },
······
}
}
# mapping properties 嵌套声明格式
{
"field0": { "type": "text" },
"field1": {
"type": "nested", // 必须是nested
"properties": {
"son_field1": {
"type": "text"
},
······
}
}
}
# 插入文档格式
PUT / POST ${index}/_doc/${id}
{
"field0": "${field0Value}",
"field1": [
{ "son_field1": "${son_fieldValue1}" }, // 本质上是类似的,
{ "son_field2": "${son_fieldValue2}"},
······
]
}
# 以数组的形式插入到文档到索引之中
PUT / POST ${index}/_doc/${id}
{
""
}
# final store
{
"field0": "field value",
"field1.son_field1": "son_field1 value",
"field1.son_field2": "son_field2 value",
······
}
嵌套类型查询格式
GET / POST ${index}/_search
{
"query": {
"bool": {
"must":
{ "term": { "${field.son_field1}": "${son_field1_value}" } },
{ "term": { "${field.son_field2}": "${son_field2_value}" } }
]
}
}
}
关于更多的介绍可以参考官方文档中对 nested 的介绍 (版本自己调):Nested field type | Elasticsearch Guide 8.15 | Elastic
父子类型
es提供了join数据类型,来表达文档之间的父子对象关系。其中父文档和子文档之间的关系一般是相互独立的,并且可以通过类似于引用的方式进行绑定。 (这样做的好处当然是两个数据之间是相互独立的 [甚至搜索的时候都是独立的],基本不存在相互影响的可能;而坏处当然也非常明显,需要额外的资源来实现两者之间的记录)
显然的在父子类型下,一般适用于 user - operate(某种行为) 类似场景下使用的情况偏多,在这种情况下往往是子文档的修改或者更新的频率较高。并且需要注意的是父子类型因为需要额外的资源来记录两个文档之间的关系,在实际查询的时候,父子性能查询效果其实较低,一般适合更新子文档多,但是查询少的场景(相对于nested类型来说)
父子类型声明
// 基本的父子类型的定义
"mappings": {
"properties": {
"${field0}": { "type": "$[keyword / integer ······]" },
"${field1}": { "type": "$[keyword / integer ······]" },
"${field2}":{
"type": "join",
"relations": {
"${parent_field [跟field0 / field1无关系]}": "${child_field [跟field0 / field1无关系]}"
}
}
······
},
······
}
// 示例 (构建内包含 join 类型的字段)
"mappings": {
"properties": {
"${field0}": {"type": "text"},
"${field1}": {"type": "text"},
"${field2}": {
"type": "join",
"relations": {
"${parent}": "${child}"
}
}
}
}
// 索引父文档内容 (插入新父文档)
// 实际上是将当前索引的整个文档都当做父文档进行记录 (包含:field0、field1 ······)
PUT / POST ${index}/_doc/${parent_id}
{
"${field0}": "${field0_value}",
"${field1}": "${field1_value}",
"${field2}": {
"name": "${parent}",
}
}
// 索引子文档内容 (插入新子文档) [插入子文档数据时,必须跟父文档的id是一致的,否则可能找不到子文档]
// 实际上是将当前索引的整个文档都当做子文档进行记录 (包含:field0、field1 ······)
PUT / POST ${index}/_doc/${id}?routing=${parent_id}
{
"${field0}": "${field0_value}",
"${field1}": "${field1_value}",
"${field2}": {
"name": "${child}",
"parent": "${parent_id}"
}
}
父文档查询方式
// 通过 GET 方式获取parent_id的内容
GET ${index}/_doc/${parent_id}
// sample:GET join_index/_doc/1
// 通过 POST 方式获取 parent 的内容
POST join_index/_search
{
"query": {
"term": {
"_id": {
"value": 1
}
}
}
}
对于父文档的查询之中非常简单,直接像普通查询一样,通过GET / POST就可以实现父文档的查询。
针对父文档是否包含子文档的查询
// 可以查出使用目标作为父文档的子文档
POST ${index}/_search
{
"query": {
"has_parent": {
"parent_type": "${parent}", // 声明 relations 中 parent 的名字
"query": { // 需要注意的是,这里的query的参数和内容都是针对 parent 文档的
"term": {
"${parent field}": "${parent field value}" // 针对parent的查询条件
}
}
}
}
}
子文档查询方式
GET / POST ${index}/_doc/${id}?routing=${parent_id}
// sample:GET join_index/_doc/2?routing=1
// 通过 POST 方式获取 child 的内容 (通过parent的值)
POST ${index}/_search
{
"query": {
"parent_id": { // 这里的parent_id指代的是parent的id是搜索项,固定的
"type": "child",
"id": ${parent_id} // 这里的parent_id是参数
}
}
}
需要注意的是子查询的方式,必须需要通过使用 routing 进行配置,如果不针对 routing 进行配置,那么就会导致查询不到子查询的结果。
针对子文档是否存在父文档的查询
POST ${index}/_search
{
"query": {
"has_child": {
"type": "${child}", // 声明 relations 中的 child 的名字
"query": { // 需要注意的是,这里的query的参数和内容都是针对 child 文档的
"term": {
"field": {
"value": "child_field_value" // 针对parent的查询条件
}
}
}
}
}
}
关于更多的介绍可以参考官方文档中对 join 的介绍 (版本自己调):[Join field type | Elasticsearch Guide 8.15] | Elastic
地理类型
- geo_point:记录的是地理的坐标
- geo_shape:记录的是地理上的形状
数组类型
-
基本的数据类型默认的情况下就直接支持数组类型,这个时候查询只要命中其中一个就可以匹配成功
POST ${index}/_doc { "$(keywordTypeField)": ["kewordValue1", "keywordValue2", "keywordValue3"······], "$(integerTypeField)": ["intValue1", "intValue2", "intValue3"······], "$(textTypeField)": ["textValue1", "textValue2", "textValue3"······], "$(longTypeField)": ["longValue1"·······] ······ }
一看过去感觉很普通,但实际上text和其他类型的数据存在着一些不同。众所周知,es为了实现常规的数据查询和操作和提供针对text类型根据部分的词项查询的效果。内部包含两种类型的索引,正排索引和倒排索引。
正排索引
而所谓的正排索引其实就常见的能帮助我们提高查询、聚合、排序等操作的索引结构。(类似于hashMap的哈希表结构、排序过后的数组、Myiasm 和 Innodb 的 B+树结构等)
倒排索引
简单的来说,es为了实现通过字符串部分的词项直接匹配到目标字符串集,就是通过倒排索引实现的。其本身是通过分词器来实现的。在es之中是针对text类型提供的。本质上其实就是通过将整个字符串做分词,形成众多的词项,并通过词项找到原先的字符串。这个过程也会产生几个问题。(但是在这里不做过多介绍)
text类型的区别
- 针对keyword等类型的数据,es会在构建索引的时候,就构建出相对应 doc_values 并保存到磁盘之中 (实际上存储在.dvm 和 .dvd 文件)。在需要的时候,再加载到内存之中使用。针对keyword这种类型的数据的时候,es会针对这些类型的数据构建出 正排索引 (补充一点,es对于doc_values的加载其实是按需加载的,这点利用到了OS的文件系统缓存来缓存需要的数据)。
- 而针对text类型的数据,es本身不会在针对text构建 doc_values ,也正因为缺少了 doc_values 也就是默认情况下 text 是没有正排索引的。如果我们针对 text 做聚合或者是排序动作,那么就会出现报错。如果我们一定需要针对text类型的数据中聚合或者排序动作,我们可以通过修改 mapping ,允许该字段构建 fielddata 来实现针对 text 的聚合。
除非开启 text 字段的 fileddata 否则 es 是不支持针对 text 的聚合和排序,还需要注意的一点是:使用fielddata 会导致内存被大量消耗
PUT ${index}
{
"mappings": {
"properties": {
"${textFieldName}": {
"type": "text",
"fielddata": true
}
}
}
}
另外,还有一些信息是需要补充的 doc_values 是针对 keywords 一类类型实现正排索引效果的数据结构,本身会存储到磁盘之中;而 fileddata 是针对 text 一类的数据实现正排索引的效果的数据结构。
Elasticsearch API
索引级别API
| typename | description | searchKey |
|---|---|---|
| keyword | 适合简短而且有一定结构的字符串, 如短信、邮件的内容等 |
term |
| text | 较长的字符串类型的数据 | match |
| Integer | 整型 | term |
| long | 长整型 | term |
| float | 浮点型 | |
| double | 双浮点型 |
文档操作API
新建文档
使用索引新建索引文档,如果甚至还没建立索引,这里可以先创建索引。
PUT books
{
"mappings": {
"properties": {
"book_id" : {
"type": "keyword"
},
"name": {
"type": "text"
}
}
},
"settings": {
"number_of_shards": 2, # 定义了 2 个分片
"number_of_replicas": 2 # 定义了每个分片 2 个副分片
}
}
如果要使用以前的索引,直接新增数据,那么为了避免id可能出现重复导致这里不是新建而是更新的情况出现,我们可以使用以下命令,先查当前最大的id是多少。获得最大的 book_id (keyword不支持max,只能倒序获得)
POST /books/_search
{
"size": 0,
"aggs": {
"max_book_title": {
"terms": {
"field": "book_title.keyword",
"size": 1,
"order": {
"_key": "desc"
}
}
}
}
}
POST index/_doc/id
POST books/_doc/3
{
"book_id": "3",
"name": "elasticsearch?还是得学"
}
新建索引文档的方法其实在之前已经提到过了,这里为了方便直接使用了之前的索引和文档。
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : { // shards 的意思是描述在此次的操作过程之中涉及的分片及其情况
"total" : 3, // 该索引总共有多少个分片,其中第一个是主分片,其他的都是副分片
"successful" : 3, // 成功执行了多少个分片的操作
"failed" : 0 // 失败了多少个分片
},
"_seq_no" : 2, // 本质上等同于改了多少次
"_primary_term" : 2 // 本质上是描述es服务器重启或者重新选举的master 加起来的次数
}
而如果当前的id文档已经存在在索引之中,es的处理也会有所不同会从插入新的索引文档改为更新索引文档。返回的信息如下: (显然result从create变更为updated)
{
"_index" : "books",
"_type" : "_doc",
"_id" : "3",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}
除了通过 post indexName/_doc/id 或者 post indexName/ _doc 可以创建新的索引文档以外,还可以通过使用 put 命令来实现
PUT index/_create/id
PUT books/_create/4
{
"book_id": "4",
"name": "好好好"
}
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "4",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 3
}
PUT index/_doc/id
PUT books/_doc/5
{
"book_id": "5",
"name": "不是,哥们"
}
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 3
}
三种方式总结
| 方式 | 特性描述 | 特点 |
|---|---|---|
| PUT books/_doc/id | Create API使用 PUT 方式创建文档, 如果文档存在,会先删除再写入 PUT _doc 一定要有ID,否则就会报错 Incorrect HTTP method for uri 报错 status 405 |
一般不用 推荐用POST + id |
| PUT books/_create/id | Create API之中使用 PUT 的方式创建文档, PUT _create 没有ID,就会出现报错 Incorrect HTTP method for uri 报错 status 405 PUT _create 如果已经存在该ID文档,就会报错 version_conflict_engine_exception 报错 status 409 |
有唯一性校验 |
| POST books/ _doc / id POST books/ _doc |
Create API之中使用 POST 方式创建文档, 可以指定ID也可以不指定(不指定自动生成) 如果是指定ID,那么已经存在该ID的文档的时候, 就会直接删除原先文档,然后在新建一个。 |
不考虑是否存在 效率最高 |
查询文档
这里仅仅教一下最简单的如何发起查询请求,但是并不详细介绍查询匹配的写法和规则等,如有需要可以查看下面的 全文索引API的内容
ID查询
GET index/_doc/id
GET books/_doc/id
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "4",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 3,
"found" : true,
"_source" : {
"book_id" : "4",
"name" : "不是,哥们"
}
}
GET 参数
| 参数 | 简介 |
|---|---|
| perference | 默认的情况下,GET API会从多个副本之中随机挑选一个, 但如果使用perference就可以控制GET请求最终分配到哪一个分片执行 |
| realtime | 控制 GET 请求是实时的还是准实时的,默认是true |
| refresh | 是否在执行 GET 操作前执行 refresh (更追求实时) |
| routing | 自定义 routing key 是用于指定文档在集群中存储时的路由方式, 在GET之中routing参数的作用是一般是优化查询性能和数据分布 一般是 POST 插入的时候使用 routing GET的时候就会需要 routing 配合 Such as: GET /${indexName}/_doc/1?routing=customerN |
| stored_fields | 返回在 Mapping 之中 store 设置为 true 的字段,而不是 _source,默认为 false |
| _source | 指定是否返回 _source 指定的字段 (组合以下 _source_excludes / _source_includes 使用) |
| _source_excludes | 指定不返回什么字段,当 _source 为 true 的时候使用 |
| _source_includes | 指定返回什么字段,当 _source 为 true 的时候使用 |
| version | 指定版本号,如果获取的文档的版本号与指定的不一样的时候,直接返回 http 409 |
批量查询
POST/GET index/_search
先不废话,这里直接先把好用的模板直接贴上来
GET ${index}/_search
{
"size": 100,
/* 排序 , 这里的elementProperties 可以是 _id、也可以是_source内部的列
"sort": [
{ "${elementProperties}": "asc/desc" },
{ "${elementProperties}": "asc/desc" },
]
*/
/* 查询某些列 这里的includes当然只能是 _source结果内部的列
"_source": {
"includes": ["${fieldName1}", "${fieldName2}"]
},
*/
"query": {
"match_all": {}
}
}
该查询语句可以帮助我们查询某个索引下的所有的数据,大概让我们知道目前es该索引的情况信息。
# 如果使用GET (无序)
GET /books/_search
{
"size": 100,
"query": {
"match_all": {}
}
}
# 如果使用POST (无序)
POST /books/_search
{
"size": 100,
"query": {
"match_all": {}
}
}
# 如果需要指定某一部分字段返回
GET /your_index/_search
{
"size": 100,
"_source": true, // 默认情况下ES查询就是 _source = true
// 如果是false,则无法看到我们实际存储的数据
"query": {
"match_all": {}
}
}
# 如果需要排序 假设是 id 升序排序
GET /your_index/_search
{
"size": 100,
"sort": [
{ "_id": "asc / desc" }
],
"query": {
"match_all": {}
}
}
# 如果只要特定字段的信息 当然需要注意的是,这里的_source: ["$filedName"] 其实是简化过的
# 最标准的写法可以参考更下面一个
GET books/_search
{
"size": 100,
"_source": ["name"],
"query": {
"match_all": {}
}
}
GET books/_search
{
"size": 100,
"_source": {
"includes": ["${fieldName1}", "${fieldName2}"]
},
"query": {
"match_all": {}
}
}
MGET
当我们需要通过多个文档ID同时获取多个文档的信息的时候,如果我们还是使用GET API的话,我们就会需要多次发起请求,这样的结果就是效率会非常低,还需要自己组装起来。但如果使用MGET就能直接解决该问题。
# 1. 在 docs 的 body 之中指定 index
# GET /_mget { "docs": ["_index": ${indexName}, "_id": ${id} ]
GET /_mget
{
"docs": [
{ "_index": "books", "_id": "1" },
{ "_index": "books", "_id": "2" }
]
}
# 2. 当然也可以 前缀 上直接指定 index 不在 docs 的 body 之中再指定
GET /${indexName}/_doc/_mget
GET /books/_mget
{
"ids": ["1", "2"]
}
# 这两个方式的结果是一样的
{
"docs" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"book_id" : "1",
"name" : "elasticsearch 从入门到放弃学习"
}
},
{
"_index" : "books",
··· ···
"_source" : {
"book_id" : "2",
"name" : "elasticsearch 学牛魔,开摆"
}
}
]
}
更新文档
当然除了插入和获取以外,针对elasticsearch索引之中的文档经常还会有更新的操作。但需要注意的是es的更新操作时跟mysql等关系型数据库一样,同时支持携带 id 更新和不携带 id 更新两种方案。
ID更新
POST index/_doc/id
该方法前面其实已经说过了,就是插入方式之中的一种,直接指定某个id,如果已经存在那么 es 会直接删除原先已经存在的文档重新搞一个新的。 (但是这样实现有一个非常显然的问题,我们更新一定会导致文档所有的字段都被更新一遍)
POST books/_doc/4
{
"book_id": "4",
"name": "好好好"
}
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 4
}
POST index/_update/id
为了实现只更新部分字段的值,允许我们通过 _update 直接更新我们的文档
POST books/_update/5
{
"doc": {
"name": "诗人握持"
}
}
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 4
}
条件更新
POST index/_update_by_query
如果我们不知道 id 但是知道一些其他字段的值,我们也可以通过 update_by_query 来实现更新效果,但是使用的关键字就需要从_doc 修改为 _update_by_query ,他的实际意思是,将 book_id 值为 5 的数据,利用 painless 脚本协助将其的 name 修改为 某个值。
POST books/_update_by_query
{
"query": {
"term": {
"book_id" : {
"value": "5"
}
}
},
"script": {
"source": "ctx._source.name='就这?'",
"lang": "painless"
}
}
显然的如果我们的更新方式从id变为非id条件的更新的时候,就可能会出现大量数据被匹配成功导致es需要时间进行修改的情况出现,但是在es之中由于请求都是走的网络请求进行处理,那么就势必会出现 请求超时 的可能性,为了解决该问题,es官方提供了参数 wait_for_completion ,将其设置为 true 就先获得 任务id ,在后续处理之中在查询 task_id 知道是否已经完成该任务。
POST books/_update_by_query?wait_for_completion=false
{
"query": {
"match_phrase": {
"name": "哥们就这?"
}
},
"script": {
"source": "ctx._source.name='诗人握持'",
"lang": "painless"
}
}
}
执行结果
{
"task" : "wbS5y0jDSGq9LU0JIddDuw:311880"
}
通过 GET 命令再获取当前 task 是否执行完毕
GET /_tasks/wbS5y0jDSGq9LU0JIddDuw:308389
查询结果 (成功示例)
{
"completed" : true,
"task" : {
"node" : "wbS5y0jDSGq9LU0JIddDuw",
"id" : 311880,
"type" : "transport",
"action" : "indices:data/write/update/byquery",
"status" : {
"total" : 1,
"updated" : 1,
"created" : 0,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0
},
"description" : "update-by-query [books] updated with Script{type=inline, lang='painless', idOrCode='ctx._source.name='诗人握持'', options={}, params={}}",
"start_time_in_millis" : 1726161017445,
"running_time_in_nanos" : 182169113,
"cancellable" : true,
"headers" : { }
},
"response" : {
"took" : 182,
"timed_out" : false,
"total" : 1,
"updated" : 1,
"created" : 0,
"deleted" : 0,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled" : "0s",
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until" : "0s",
"throttled_until_millis" : 0,
"failures" : [ ]
}
}
删除文档
当然跟关系型数据库对应的是,我们也经常需要将一些数据从库之中删除掉一样,es之中我们同样也需要将一些文档从索引之中删除掉。
ID删除
DELETE index/_doc/id
DELETE books/_doc/5
执行结果
{
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_version" : 5,
"result" : "deleted",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 5
}
当然除了更新我们可以通过使用 id 来实现数据更新以外,删除也可以让我们支持通过条件查询的方式来删除数据。elasticsearch还支持了 _delete_by_query 关键字来进行查询删除数据。
条件删除
POST index/_delete
POST books/_delete_for_query
{
"query": {
"term": {
"book_id": "5"
}
}
}
执行结果 (删除成功)
{
"took" : 566,
"timed_out" : false,
"total" : 1,
"deleted" : 1,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
当然跟获取一样的,如果我们的查询辨析度较低,或者说我们的数据有可能会影响大量的数据的情况下,在ES的网络请求的基本背景之下,我们的查询就必定存在超时的可能性。因此我们一样可以在 POST 的 _delete_for_query 的后续追加参数 ?wait_for_completion=false ,并且通过使用 GET _task/${task_string}
POST books/_delete_by_query?wait_for_completion=false
{
"query": {
"match_phrase": {
"name": "诗人握持"
}
}
}
GET _tasks/wbS5y0jDSGq9LU0JIddDuw:15575
// 后续就可以查看执行的效果如何
批量操作文档
当然除了我们正常的单个文件的修改以外,还会有需要修改多个文档的场景,在该场景下,我们可以通过使用 Bulk API 来批量处理文档。Bulk API支持在一次调用之中操作不同的索引,使用的时候可以在 Body 之中指定索引。因此本质上批量操作文档上支持了除了查询以外的多种操作:1. Index 2. Create 3. Update 4. Delete 四种不同的操作。
所以,需要注意的一点是。由于新建文档 / 更新文档 / 删除文档跟查询文档本质上有所不同,查询文档包含MGET批量查询命令,但是其他的操作都没有,所以其他的所有批量操作本质上都是需要使用 _bulk 来实现的
POST _bulk
如果我们需要通过 Bulk 一次插入多条数据 或者 一次更新多条数据 或者 一条删除多条数据。又或者直接糅杂不同的操作,比如在一条 bulk 之中插入、修改、删除等读条操作合并 (也可以新增索引,但是一般很少会有人这样写)
批量插入多条数据
可以通过使用 _bulk 根据 index 和 document body 组成请求体,就可以实现批量新增的效果。但是需要注意一点是,这里的 document body 是一定要保持这个格式的,不可以拆分成 跨行的 json 花括号,如果这样拆解就会出现 illegalException / json_e_o_f_exception 的情况。
POST _bulk
{ "index" : { "_index" : "books", "_id" : "1" } }
{ "book_id": "5", "name": "芜湖,起飞" }
{ "index": { "_index": "books", "_id": "6" } }
{ "book_id": "6", "name": "manba out!" }
{ "create": { "_index": "books", "_id": "8" } }
{ "book_id": "8", "name": "zzzzz"}
执行结果
{
"took" : 4,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_version" : 2,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 26,
"_primary_term" : 5,
"status" : 201
}
},
{
"index" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "6",
"_version" : 6,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 27,
"_primary_term" : 5,
"status" : 201
}
},
{
"create" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "8",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 5,
"status" : 201
}
}
]
}
批量操作数据
以下做一个类似于脚本的批量语句执行操作。(需要注意的是 _bulk 不支持脱离 id 本身对数据进行操作,也就是我们无法在 _bulk 之中包含类似于 更新文档 \ 删除文档一样的 _update_for_query \ _delete_for_query)
POST _bulk
{ "index": { "_index": "books", "_id": "7" } }
{ "book_id": "7", "name": "不是,哥们,你认真的?"}
{ "delete": { "_index": "books", "_id": "5"} }
{ "update": { "_index": "books", "_id": "7"} }
{ "doc": {"book_id": "6", "name": "不是,哥们,你认真的? 7 - 6"}}
执行结果
{
"took" : 23,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "7",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 28,
"_primary_term" : 5,
"status" : 201
}
},
{
"delete" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "5",
"_version" : 3,
"result" : "deleted",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 29,
"_primary_term" : 5,
"status" : 200
}
},
{
"update" : {
"_index" : "books",
"_type" : "_doc",
"_id" : "7",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"_seq_no" : 30,
"_primary_term" : 5,
"status" : 200
}
}
]
}
全文索引API
一般来说,我们在进行查询的时候,往往不是精确匹配的,一般来说是是通过分词器进行分词,然后再进行匹配的。最后再根据相关性做关联做的统计结果。
MATCH ALL
- MATCH ALL不做任何检索,所有匹配都命中,一般用于全部返回的时候
MATCH
-
MATCH elasticsearch 会首先将 context 部分进行拆解(使用分词器),然后对拆解出来的词语去进行 or 匹配,只要其中一个词语本身能匹配成功那就返回。
- 完整介绍:匹配查询可以处理全文本、精确字段 (日期、数字等)
such as:
GET ${index}/_search { "query": { "match": { "${filed}": "quick brown fox" /* ,"operator": "and" // 使用operator可以将匹配规则从or修改为and ,"minimum_should_match": "n 或者 n%" // 使用minimum_should_match可以要求被匹配的数据之中 // 最少出现分词之中的几个词语 // 像示例之中的 quick brown fox,设置为2 或者 大于67%那就是必须有两个 */ } } }效果:一般来说会被拆解为 quick brown fox 三个词项,然后分别匹配只要数据某个字段之中包含有 quick / brown / fox,那么就会被返回。
MATCH PHRASE
-
MATCH PHRASE elasticsearch 会将整个查询之中的语句作为一个短语进行查询,也就是直接查询是否有数据直接包含查询的句子的。
另外 MATCH PHRASE 还支持 slop 进行配置,允许词项之间存在其他词间隔,以下会详细介绍 slop 如何配置等信息。-
在不使用 slop: n 参数的情况下:在执行结果上完全等效于关系型数据库之中的 '%${searchValue}%' (默认 slop : 0)
-
在使用 slop: n 参数的情况下:其执行结果就等同于 '%{searchValueWord1} 可以有i1个词 {searchValueWord2} 可以有i2个词
${searchValueWord3}······%' (但始终 i1 + i2 + i3 ······ <= n)
简单的来说就是,在使用 slop: n 的时候, elasticsearch首先还是会通过分词器先将 词语拆分出各个词项,然后 slop: n 的意思其实是允许目标文本在各个词项之间插入 n个其他的词 (词项的顺序仍然不可变)such as:
# 无 slop 例子 GET ${index}/_search { "query": { "match_phrase": { "${filed}": "elasticsearch 学" } } } # 使用 slop 例子 GET ${index}/_search { "query": { "match_phrase": { "${field}": { "query": "${searchValue}", "slop": n } } } }效果:
在前面的介绍之中,我们建立过一个 books 的索引,现在依据使用该索引作为展示。在之前曾经往该索引添加过两个文档 ( _id:2 _source: {"book_id": "2", "name": "elasticsearch 学牛魔,开摆"} 和 _id:3 _source: {"book_id": "3", "name": "elasticsearch?还是得学"} )
根据 match_phrase 进行查询,并可以将 ${searchValue} 替换为:elasticsearch 学 让es拆解为 elasticsearch 和 学两个分词:
如果我们不设置 slop,那么最终命中的只有 _id:2 的数据项。(因为只有2的 name 直接包含了 searchValue的短语)如果我们设置slop为3或者3以上,就可以成功将 _id:3 的数据项匹配成功。("?还是得" 去掉标点符号之后刚好剩下三个词 [词 ≠ 一个字 只是这个例子中是而已])
- 完整介绍:短语匹配会将检索内容分词,这些词语必须全部都出现在了检索内容之中,并且顺序全部一致,默认的情况下也要求这些词本身是连续的。
-
MATCH PHRASE PREFIX
-
MATCH PHRASE PERFIX 本质上跟match_phrase几乎完全一样,唯一不同的点在于,match_phrase_prefix 回家过分词器分词结果的最后一个词项作为后续部分的前缀,也就是 quick brown f 会匹配 quick brown 后以 f 作为开发的文档字段,后续拼接的是不同的字符的数量,一般来说是按照字符顺序来拼接计算的,如果目前是有 a b c d e f 如果配置的是三,那就匹配到 a b c。而这个是MATCH PHRASE PERFIX无法实现的。
跟MATCH_PHRASE类似的,都有一个较为特殊的参数配置,max_expansions 通过该参数可以配置匹配成功数据的条数在一定的数量,默认的情况下这个值是50。我们可以使用 max_expansions 限制返回的数据的条数。
需要注意的是,max_expansions 的限制是允许每一个分片返回 设置的n条数据,而不是所有的总和
如果我们想要实现更加详细的前缀查询效果就不能单纯使用 match_phrase_prefix 可以通过使用 Suggest API实现
- 为什么不直接使用 size 来进行限制,而是非要多此一举使用 max_expansions 呢?
看着size 和 max_expansions 是相似的,但其实这两个并不完全一样。
max_expansions:限制的效果是限制在最后一个词项进行匹配的时候,限制匹配到的词条,这样做的效果本质上是限制了需要处理的数量,这样的效果还能影响索引的扫描范围。(因为前缀查询,很有可能匹配到大量的数据,在处理阶段可能会出现大量的文档)
such as:
# 不使用 max_expansions 限制匹配条数 GET ${index}/_search { "query": { "match_phrase_prefix": { "${field}": { "query": "${searchValue}" } } } } # 使用 max_expansions 限制匹配条数 GET ${index}/_search { "query": { "match_phrase_prefix": { "${field}": { "query": "${searchValue}", "max_expansions": n // 当然这里也是可以使用 slop 的 /* , "slop": n */ } } } }效果:
在前面的介绍之中,我们建立过一个 books 的索引,现在依据使用该索引作为展示。在之前曾经往该索引添加过两个文档 为了更好的演示,我添加了以下的数据: {"book_id": "8 + 1 (逐个加1)", "name": "elasticsearch t[a-z]est1"},最终添加了十来条数
这里我们将 {field} 设置为 name,将 {searchValue} 设置成 elasticsearch t 再进行查询,先不设置max_expansions,可以得到以下的total,显然的是所有的数据都能成功查询出来。(从 a - i 所有刚添加的数据都被成功查询出来了)
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 2, "successful" : 2, ······ }, "hits" : { "total" : { "value" : 9, "relation" : "eq" }, ··· ··· "hits" : [ { "_index" : "books", "_type" : "_doc", "_id" : "IV2O8ZEBjKOqwPdUI6Cp", "_score" : 11.075979, "_source" : { "book_id" : "10", "name" : "elasticsearch taest1" } }, { "_index" : "books", "_type" : "_doc", "_id" : "I12O8ZEBjKOqwPdUQ6Bu", "_score" : 11.075979, "_source" : { "book_id" : "12", "name" : "elasticsearch tcest1" } }, ··· ···而如果我们后加上 max_expansions ,配置为1之后,我们查出来的总数直接就被限制了。(但是需要注意的是,我们实际上查询的时候,使用到的 数据分片是 两个 (_shards total :2) 所以一定是包含了两种不同后缀的文档数据,有点难以提前知道是什么后缀会被查出来)
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 2, "successful" : 2, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 2.8941627, "hits" : [ { "_index" : "books", "_type" : "_doc", "_id" : "Il2O8ZEBjKOqwPdUM6Cf", "_score" : 2.8941627, "_source" : { "book_id" : "11", "name" : "elasticsearch tbest1" } }, { "_index" : "books", "_type" : "_doc", "_id" : "IV2O8ZEBjKOqwPdUI6Cp", "_score" : 2.1171818, "_source" : { "book_id" : "10", "name" : "elasticsearch taest1" } } ] } }显然的,在我测试这一次被查询出来的是taest1 和 tbest1,在我的测试之中,如果我将 max_expansions 设置为 2 ,那么实际上 就可以成功查出来 四种 不同后缀的词项。(当然如果运气足够好,两个分片返回查询的是同一个字符后缀开头,那么其实也有可能只返回一条数据)
- 完整介绍:和match phrase本身是类似的,但是会把最有一个词项本身作为前缀,并且会匹配这个词项开头的任何词语
- 为什么不直接使用 size 来进行限制,而是非要多此一举使用 max_expansions 呢?
MULTI MATCH
-
MULTI MATCH 当不确定是哪一个文本字段有这些词的时候 ,可以使用该匹配方式,在使用这个匹配方式的效果下,可以使得我们的查询针对多个字段都进行查询,只要任一指定字段之中存在,即可认为匹配成功。
另外 MULTI MATCH还额外支持针对不同的字段设置不同的字段权重,从而实现相关程度上的评分处理。设置权重的方式也很简单,只需要我们在写查询的字段的时候,添加 " ^n " 即可,如果是 ^2 就是相关程序 * 2在以下的测试之中,都是依靠在这两条数据的基础上实现的。 {"_id": ‘"J12f8ZEBjKOqwPdUiKBD", "book_id": "16", ”name" : "elasticsearch tb 114.514 est"} 和 {"_id": "Il2O8ZEBjKOqwPdUM6Cf", "book_id": "114.514", "name": "elasticsearch tbest1" } 和 如
果有需要可以自己通过 POST index _update 修改
在MULTI MATCH之中,我们还可以配置查询的类型(一般是以下几种类型):
-
best_fields :默认type,按照最匹配的一个文档字段进行评分统计。
GET books/_search { /* "explain": true, */ "query": { "multi_match": { "query": "114.514", "fields": ["book_id", "name"], "type": "best_fields / most_fields / phrase / phrase_prefix / cross_fields / bool_prefix", "tie_breaker": n # 0.1 - 1.0 } } }{ ······ "_shards" : { "total" : 2, "successful" : 2, ····· }, "hits" : { "total" : { ······ }, "max_score" : 1.9717476, "hits" : [ { ······ "_id" : "J12f8ZEBjKOqwPdUiKBD", "_score" : 1.9717476, "_source" : { "book_id" : "16", "name" : "elasticsearch tb 114.514 est" } }, { ······ "_id" : "Il2O8ZEBjKOqwPdUM6Cf", "_score" : 1.4816045, "_source" : { "book_id" : "114.514", "name" : "elasticsearch tbest1" } }, { ······ "_id" : "IF2O8ZEBjKOqwPdUEaDZ", "_score" : 1.4816045, "_source" : { "book_id" : "114.514", "name" : "elasticsearch ti 114.514 est" } ······ } -
most_fields:将所有有所匹配的文档都返回,并且会计算所有涉及字段的匹配分数的总和。
{ ······ "_shards" : { "total" : 2, "successful" : 2, ······ }, "hits" : { "total" : { ······ }, "max_score" : 3.326457, "hits" : [ { ······ "_id" : "IF2O8ZEBjKOqwPdUEaDZ", "_score" : 3.326457, // 显然的是两个都成功匹配到最终统计的结果 "_source" : { "book_id" : "114.514", "name" : "elasticsearch ti 114.514 est" } }, { ······ "_id" : "J12f8ZEBjKOqwPdUiKBD", "_score" : 1.9717476, "_source" : { "book_id" : "16", "name" : "elasticsearch tb 114.514 est" } }, { ······ "_id" : "Il2O8ZEBjKOqwPdUM6Cf", "_score" : 1.4816045, "_source" : { "book_id" : "114.514", "name" : "elasticsearch tbest1" } ······ } -
phrase:在所有涉及的文档的字段上分别进行各自 的 match_phrase 。
跟 match_phrase 类似,这里不做过多的介绍
-
phrase_prefix:在所有涉及的文档字段上分别进行各自的 match_phrase_prefix 。
本质上其实和 match_phrase_prefix 是一致的,甚至也可以添加 max_expansions 参数做前缀搜索数量的限制。GET books/_search { "query": { "multi_match": { "query": "elasticsearch t", "fields": ["name"], "type": "phrase_prefix", "max_expansions": 1 } } }查询结果:
{ ······ "_shards" : { "total" : 2, "successful" : 2, ······ }, "hits" : { "total" : { ······ }, "max_score" : 2.4149125, "hits" : [ { ······ "_id" : "IV2O8ZEBjKOqwPdUI6Cp", "_score" : 2.4149125, "_source" : { "book_id" : "10", "name" : "elasticsearch taest1" } }, { ······ "_id" : "Il2O8ZEBjKOqwPdUM6Cf", "_score" : 2.3287106, "_source" : { "book_id" : "114.514", "name" : "elasticsearch tbest1" } ······ } -
cross_fiedls:它会将所有字段组成一个大的字段,并再各自内部查询 词。
本质上 cross_fields 其实更适合使用在需要拼接字段查询的时候使用 (更简单的来说其实就是类似于地址拆分成多个字段存储的情况,类似于 地址1 + 地址2 + 地址3。而我们提供的两个词项,一个位于地址2 一个位于地址3 之中,需要将文档查出来的场景下使用。)
需要注意的是 cross_fields 也会将query拆成词项来进行查询,这一点也是需要知悉的,并且原则是 match 而不是 match_phrase)GET books/_search { "query": { "multi_match": { "query": "16 elasticsearch", "fields": ["book_id", "name"], "type": "cross_fields" } } }查询结果
{ ······ "_shards" : { "total" : 2, "successful" : 2, ······ }, "hits" : { "total" : { ······ }, "max_score" : 0.4783222, "hits" : [ { ······ "_id" : "Jl2f8ZEBjKOqwPdUcqAZ", "_score" : 0.4783222, "_source" : { "book_id" : "15", "name" : "elasticsearch tfest1" } }, { ······ "_id" : "Il2O8ZEBjKOqwPdUM6Cf", "_score" : 0.4783222, "_source" : { "book_id" : "114.514", "name" : "elasticsearch tbest1" } }, { ······ "_id" : "J12f8ZEBjKOqwPdUiKBD", "_score" : 0.37901655, "_source" : { "book_id" : "16", "name" : "elasticsearch tb 114.514 est" } } ······ ] } } -
bool_prefix:在每个字段上创建一个 match_bool_prefix 进行查询,并且合并每个字段的评分作为评分结果,但是会针对最后一个词项当做 match_prefix 做前缀匹配效果的处理。(相当于改过的 match_phrase_prefix 进行处理)
本质上 bool_prefix 其实是结合了布尔查询,和前缀查询的特性,将通过分词器先对 query 进行拆分,并将拆分的结果之中的前 n - 1 词项做 布尔匹配,然后最后一个词项做前缀匹配处理。
GET books/_search { "query": { "multi_match": { "query": "16 elasticsearch tb 114", "fields": ["book_id", "name"], "type": "bool_prefix" } } }查询结果如下:
······ "_shards" : { "total" : 2, "successful" : 2, ······ }, "hits" : { "total" : { ······ }, "max_score" : 3.3507643, "hits" : [ { ······ "_id" : "J12f8ZEBjKOqwPdUiKBD", "_score" : 3.3507643, "_source" : { "book_id" : "16", "name" : "elasticsearch tb 114.514 est" } }, { ······ "_id" : "IF2O8ZEBjKOqwPdUEaDZ", "_score" : 1.2167468, "_source" : { "book_id" : "114.514", "name" : "elasticsearch ti 114.514 est" } }, ······ ] } }- 完整介绍: 通过 multi match 可以在多个字段上执行类似的查询
tie_breaker
另外,在multi match之中,如果我们想要将最终的评分统计从某单个的字段扩展到所有 multi 字段的统计的时候,我们可以通过使用 tie_breaker 来实现。当我们设置 tie_breaker 之后,我们在查询的时候最终的评分将改变为 tie_breaker * (multi其他字段的值) + 匹配计算值最高的字段
-
Question
不同的文档明明都只有一个字段命中我们的查询短语,却评分不一致?
这个部分其实设计了评分的算分模型。其中主要包含有两种算分模型:TF-IDF和BM25两大算分模型。默认的情况下使用的TF-IDF,两者主要区别在于BM25降低了词频也就是TF参数的影响,TF大到一定程度会限制在某个值不会继续无线上涨影响力
TF-IDF的核心在于:一个词的重要程度跟他在文章之中出现的频率成正比,那么这个词越是文章使用的重点,也就是得分会高。但是如果他频繁出现在其他的文档之中,那么他的得分就会越低。 更详细的可以参考下面使用 explain 的算分详情做的介绍。
关于TF-IDF在ES的具体实现可以参考官方的实现文档:TFIDFSimilarity (Lucene 8.7.0 API) (apache.org)
在上面我们设置一些type做 multi match 匹配的时候,往往得到的结果却很有意思,我们总共有三个文档,一个是 name 之中包含 114.514 一个是 book_id 之中包含有 114.514 ,最后一个是 book_id 和 name 之中都包含有 114.514 。但是由于我们的type是best_fields,所以理论上他们的得分都是一样的,实际出来之后,发现评分却从第一个之后逐个递减 (1.992430 -> 1.9717476 -> 1.4816045)。但是查阅资料之后发现,我们可以通过添加参数 explain: true 查看打分的原则。 /* 因为太长,以下仅仅贴出其中一个打分原则 */
{
"_shard" : "[books][0]",
"_node" : "59sIGdp7SMGqCo3umOyr-w",
"_index" : "books",
"_type" : "_doc",
"_id" : "Il2O8ZEBjKOqwPdUM6Cf",
"_score" : 1.9924302,
"_source" : {
"book_id" : "114.514",
"name" : "elasticsearch tbest1"
},
"_explanation" : {
"value" : 1.9924302,
"description" : "max of:",
"details" : [
{
"value" : 1.9924302,
"description" : "weight(book_id:114.514 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.9924302,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 1.9924302,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 10,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.45454544,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 1.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
大致的,我们可以看出来主要打分的其实是依靠以下的几个公式:
- score = boost * idf * tf (最终打分 根据 加权 * 逆文档频率 * 词频)
- IDF (逆文档频率) = log(1 + (N - n + 0.5) / (n + 0.5)) [N: 字段存在的总文档数、n:包含查询词的文档数]
- TF (词频) = freq / (freq + k1 * (1 - b + b * dl / avgdl)) [freq: 词在文档之中出现的次数、k1 = 词频饱和参数 、b = 长度计算参数 dl 子弹的长度 avgdl 字段的平均长度]
我们直接看score统计算法,可看到实际上es的评分的高低和字段在其他文档之中出现的次数是有关系的,当我们的数据在更之后被查询出来,那么我们的文档的评分也会更低。这也解释了为什么我们的文档在后查出来的评分更低的理由。
精准查询(Term)
Term Query API 返回在指定字段中准确包含了检索内容的文档,ES之中针对keyword、Integer和Date等结构性的字段饿时候,需要通过使用term查询API来实现查询。使用term和使用match的主要区别其实体现在,如果我们目标字段是text类型,那么默认情况es会将其进行分析,一般来说就会使用match进行查询;但是如果我们的目标字段是keyword类型的字段的时候,就不会被分析,同时会更加适合通过 term 进行查询。
match查询的体现:match查询会针对字符串进行分析,通过分词器对其进行分解成词条或者是词项再查询。
term查询的体现:term查询不会对查询字符串拆分,再查询。
Term Query:返回在指定字段中准确包含检索内容的文档
Terms Query:跟 Term Query 类似,不过可以同时检索多个词项的功能
Range Query:范围查询
Exist Query:返回在指定字段上有值的文档,一般用于过滤没有值的文档。
Prefix Query:返回在指定字段之中包含指定前缀的文档
Wildcard Query:通配符查询
Term Query
Term Query API 返回在指定字段中准确包含了检索内容的文档,你可以使用此 API 去查询精确值的字段,如书本ID、价格等,但是我们必须要了解的是,如果我们将term查询使用在text类型上,就会出现报错。
必须避免term用在text字段上
POST ${index}/_search
{
"query": {
"term": {
"book_id": {
"value": "16"
}
}
}
}
执行结果
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "J12f8ZEBjKOqwPdUiKBD",
"_score" : 1.4816045,
"_source" : {
"book_id" : "16",
"name" : "elasticsearch tb 114.514 est"
}
}
]
Terms Query
Terms Query 的功能跟 Term Query 类似,不过可以同时检索多个词项的功能。比如如果需要进行多个查询条件的查询。查询name之中有 elasticsearch 和 114.514 两个词语的文档的时候,我们就可以使用 terms 进行查询。
本质上 Terms Query 等同于 普通关系型数据库之中的 or 查询条件 (但实际上 terms 仍然只能查询 keywor、integer、long、data、boolean 类型的数据,如果是 text 等其他类型,在输入字符串值进行查询的时候,这样查询是不生效的。) 必须避免terms用在text字段上
POST ${index}/_search
{
"query": {
"terms": {
"${field}": [
"${searchValue1}",
"${searchValue2}"
]
}
}
}
``````
查询结果
```json
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "J12f8ZEBjKOqwPdUiKBD",
"_score" : 1.0,
"_source" : {
"book_id" : "16",
"name" : "elasticsearch tb 114.514 est"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "IF2O8ZEBjKOqwPdUEaDZ",
"_score" : 1.0,
"_source" : {
"book_id" : "114.514",
"name" : "elasticsearch ti 114.514 est"
}
}
]
Range Query
Range Query API 可以查询字段值符合某个范围区间之中的文档数据,如果比如需要将编号 1 - 15 的书本查出来,或者需要查询 0 - 50 以内的书本查出来等情况都可以使用该API进行查询。
- gt:表示大于
- gte:表示大于或者是等于
- lt:表示小于
- lte:表示小于或者等于
POST ${index}/_search
{
"query": {
"range": {
"${field}": {
"gte": ${ >= n }, // gt: 大于某个值
"lte": ${ <= n } // lt:小于某个值
}
}
}
}
Exist Query
在使用 Exist Query API 进行查询的时候,可以指定某个字段上有值的文档,而不用查询所有的文档,往往会通过这个API来对文档做进一步的过滤减少查询锁涉及到的文档数量,从而进一步提高查询的效率而存在的。 (该term支持所有类型的字段的查询)
ExistQuery可以过滤掉以下为空的文档:
- JSON对应的某个字段的值为 NULL / 空 的时候,当然如果他是空的时候也会被判断是空的。
- 在 mapping 声明的时候,如果将某个字段设置为 index: false 的时候也会导致 判断为空
- 当字段的值的长度超过了 mapping 设置该子弹的 ignore_above 大小的时候
- 当字段的值不合理,并且 mapping 之中设置了该字段的值为 ignore_malformed 的时候。
POST ${index}/_search
{
"query": {
"exists": {
"field": "${fieldName}"
}
}
}
Prefix Query
(应当符合最左匹配原则) 不应当使用 *xxxx 类似形式
Prefix Query,可以让我们查询特定字段特定前缀的文档数据线查出来。该功能支持text,但是需要注意的是,prefixQuery其实是将text类型的字段会被先做分词处理,将分词的结果拆解成一个个term,然后再进行匹配。 另外值得一提的是prefix query不会针对query中的值做任何的分析,而match_phrase_query却是支持分析。另外match_phrase_query其实是支持多个词,并支持最后一个词的前缀匹配。
相比起来,prefix query的查询,更像是 SQL 的查询
POST ${index}/_search
{
"query": {
"prefix": {
"name": {
"value": "${fieldName}"
}
}
}
}
Wildcard Query
(应当符合最左匹配原则) 不应当使用 *xxxx 类似形式
Wildcard Query允许我们使用通配符表达式进行匹配,一般来说Wildcard Query支持两种通配符的配置:
- ?, 使用 ? 通配符可以匹配任意的字符
- *, 使用 * 可以匹配 0 或 多个字符
但是需要注意的是,WildcardQuery跟Prefix Query是类似的 其实是将text类型的字段会被先做分词处理,将分词的结果拆解成一个个term,然后再进行匹配 从而实现的通配符匹配效果。
Wildcard Query使用示例如下:
POST ${index}/_search
{
"query": {
"wildcard": {
"${filedName}": {
"value": "*.51?" # 可以配合 * 代表任意长度字符 ? 代表单个字符
}
}
}
}
但是需要注意的是,在Term Query API之中会Prefix Query和Wildcard Query在进行查询的时候需要扫描倒排索引之中的词项列表之中逐个扫描的方式才能真正匹配到我们需要当前查询的词项,然后正确的匹配到相对应的ID,所以本质上我们通过 Prefix Query 又或者 Wildcard Query 进行查询的时候,应当尽量保证跟从 SQL 类似的最左匹配原则的方式来进行匹配。(如果不是,在数据量较大的情况下,就会导致性能问题。)
Term / 去评分 优化
我们针对Term Level Query API进行查询的时候,存在一个问题,term往往是结构化搜索也就是往往存在一定格式化的数据,使用term进,行查询的时候,往往都是直接进行查询,在这种情况下大部分时候都是需要直接的精准匹配,而不是像text一样需要通过评分系统来实现匹配。(我们知道 es 的评分其实是相当消耗搜索的性能的,因此大部分的term的搜索都可以通此进行优化)。当然部分text我们也可以通过该配置进行优化,去掉一些评分的计算。
我们可以通过 Constant Score 将 query 转化为 filter,从而直接省略了相关性评分的算法环节,并且我们通过使用 filter 可以更大程度的有效利用缓存进行优化。本质上他的效果类似于包装,可以用它将原先会评分的查询包裹,即可去掉评分的效果。
以下两个查询本质上是等效的 (不要评分的情况下):
POST books/_search
{
"query": {
"range": {
"book_id": {
"gte": 0,
"lte": 10
}
}
}
}
可以改造为:
POST books/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"book_id": {
"gte": 0,
"lte": 12
}
}
}
// , "boost": 1.2
}
}
}
constant_score 基础 Template
POST ${index}/_search
{
"query": {
"constant_score": {
"$[filter / query]": {
"$[term / terms / range / exist / prefix / wildcard / match(一般不用)]": {
${operator struct}
}
},
"boost": n
}
}
}
需要注意的是这里出现的boost在单个查询的时候,其实是完全没有用的,他真正的效果其实是想要做到在多个查询组合结果的时候,可以通过这个来设置当前查询的预设评分,也就是说,只要符合当前查询条件的所有文档,都会被默认的设置为 n 评分的文档,可以跟别的仍然使用评分的文档组合在一起比较。
如以下例子:
POST books/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"filter": {
"term": {
"book_id": 14
}
},
"boost": 1.2
}
},
{
"match": {
"name": "哥们"
}
}
]
}
}
}
最终结果如下:
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.4299998,
"hits" : [
{
"_index" : "books",
"_type" : "_doc",
"_id" : "7",
"_score" : 2.4299998,
"_source" : {
"book_id" : "6",
"name" : "不是,哥们,你认真的? 7 - 6"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "JV2f8ZEBjKOqwPdUW6Cb",
"_score" : 1.2,
"_source" : {
"book_id" : "14",
"name" : "elasticsearch teest1"
}
}
]
}
}
这里的boost刚好能很好地引出以下的较为复杂的查询,这里的查询方式就是组合查询。