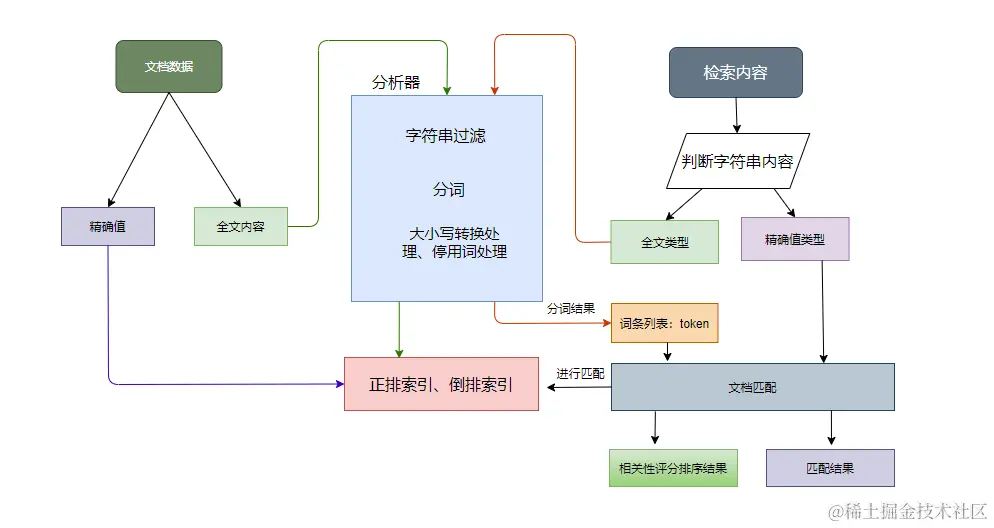
ES索引
倒排索引的实现
问题
倒排索引的实现问题,涉及到存储、快速定位词项本身、词项匹配文档数
- 分词形成的词项(term)可能是海量的,需要可以在内存和磁盘上高效存储;
- 既然词项是海量的,那么如何快速找到对应的词项也是个问题;
- 每个词项对应的文档数可能非常多,也就是上图中文档列表的链表很长;
- 在词项对应的文档多的情况下,多个文档列表间做交集的效率将是个挑战。
分词的存储结果和针对词项做快速定位其实是通过 构造词项的索引 (Term Index) 来实现的,而词项对应的文档多,多文档的匹配问题,则是通过 Roaring Bitmaps、跳表等实现的。
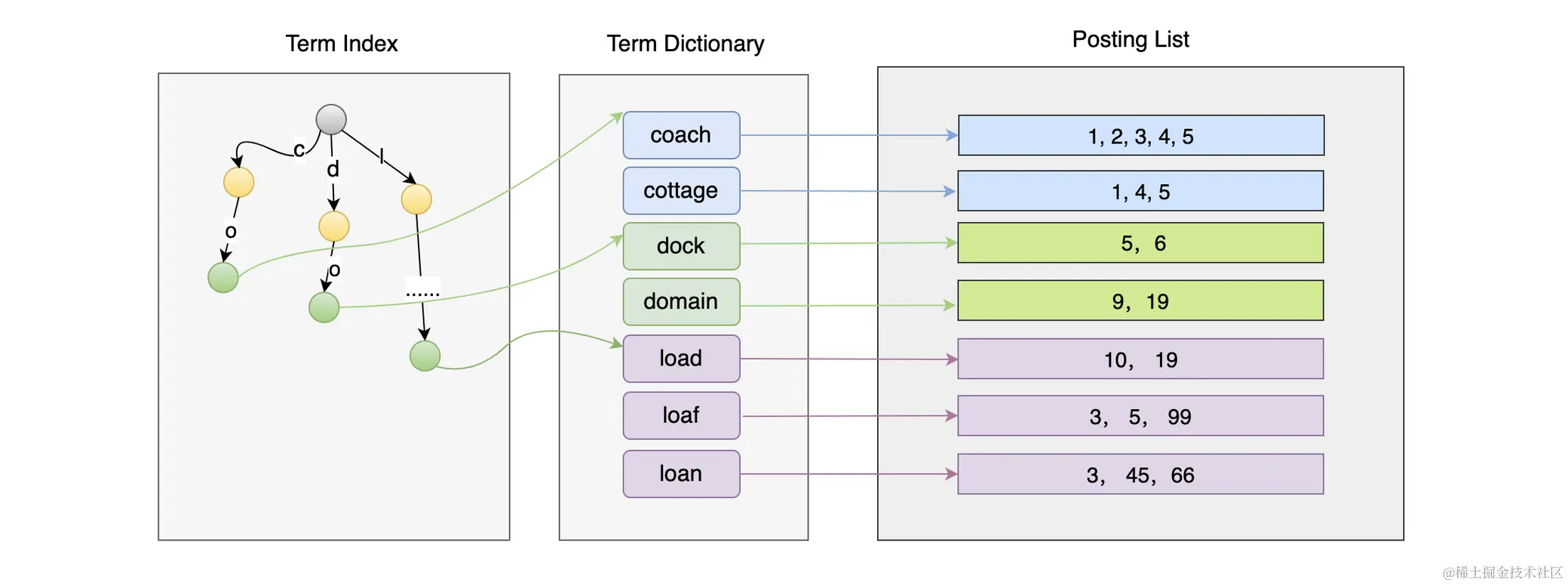
倒排索引的组成
- Term Index (针对众多的词项构造索引) 【往往会加载到 缓存之中】
- Term Dictionary (存储词项本身)
- Posting List (通过 Term Dictionary 词项本身可以找到目标匹配文档) 【涉及到压缩、Roaring Bitmaps、跳表的部分】
es中快速定位到文档本身的过程可以参考下图 (其中 Posting List 做了很大的简化,只显示了其中的id)
ES中实际存储格式
需要注意的一点是,上面的图仅仅适用于倒排索引的结构图,而并代表着实际es在存储和缓存层面的样子,实际上es针对索引之中的field都构建了完整的term index -> term dictionary -> posting list的三层层级结构的。就如下图详情可以参考下图
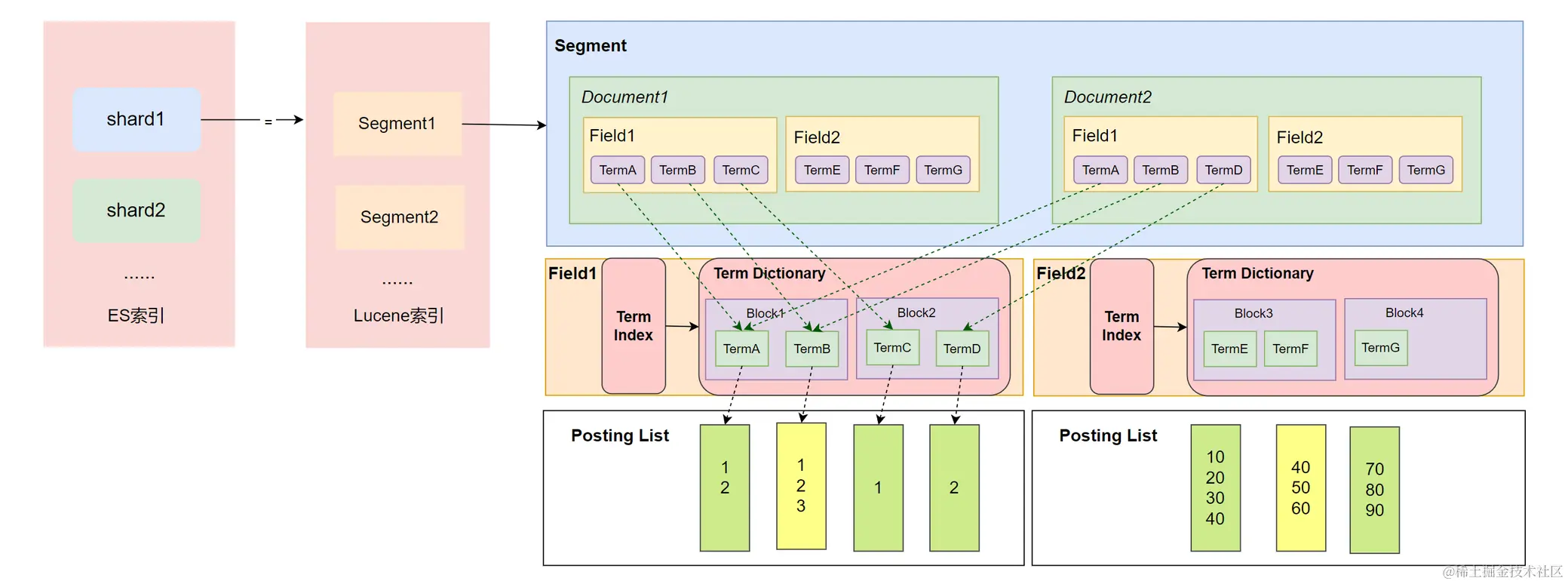
Term Index实现简单介绍
以前在研究过屏蔽词的时候,了解过一种谷歌开发过的算法技术,叫做其中包含以下几种: trie树(又叫做字典树、前缀树、单词查找树等)、Aho-Corasick(底层实现类似于Trie)、暴力、KMP算法。而es之中实现词项索引实现方式其实也是类似于trie一样的前缀索引结构,被称为 FST (本质上是 FSM 又被叫做有限状态机)。
FST实现了两个基本的功能:
- 快速知道词项是否存在,不用到term dictionary中再判断
- 快速将数据定位到词项 位于 Term Dictionary 之中 Block 的位置。
从结构上来看就是通过前缀索引的方式构建出类似于树的结构,从而实现的前缀树匹配效果 (不用管这么多,稍微看一下)
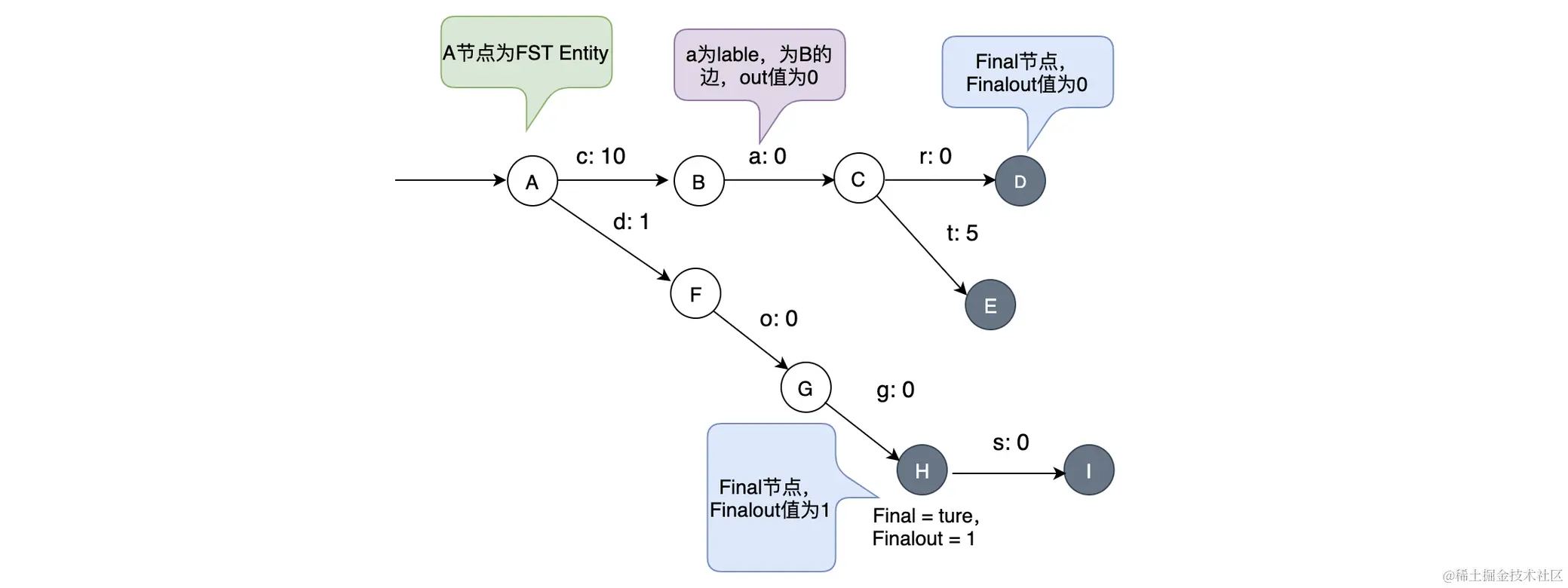
Term Dictionary实现简单介绍
在倒排索引的实现之中,Term Dictionary之中实际上保留着 Term 和 Posting List 之间的映射关系,内部会记录Term相关的信息,包括该Term相关的文档数量、Term在整个Segment之中出现的频率、还包含了指向 Posting List 对应文件的指针本身等。(文档ID列表的位置,词频位置等)
Term Dictionary构建索引的时候,会将所有 Term 进行排序,然后将Term公共部分一层层抽取,构建出类似于字典一样的格式的前缀。从而构成Term之中的 FST 数据索引格式。
Posting List实现简单介绍
上面 Posting List 提到的格式之中,并不止单单存储了数据目标的ID,其实还包含有数据的其他字段。类似于Myiasm引擎,ES使用的Lucene也将保存文件做了拆分。(分为3个不同类型的文件 【Myiasm拆为 .frm .dat .idx】)
- .pos文件:记录Term在doc之中位置信息
- .pay文件:记录Payload信息和Term在doc文件的位置信息
- .doc文件:记录文档的ID和Term词项的词频,还会额外记录跳表之中对应位置的信息,用来帮忙快速查询和定位。另外还会记录 term 在其他两个文件之中的位置
pay文件之中记录的Payload,其实就是指代我们文档之中的信息,比如:时间戳、词条权重、分类、评分信息等信息。本质上是Lucene提供的,如果想要配置这些功能需要通过配置 token filter 等自定义配置实现 (可以参考自定义模板示例)
数据压缩
利用整数压缩,优化出 VIntBlock 和 PackedBlock 对数据的游湖
在Posting List之中,因为分词实现的功能势必会存在大量词项等问题,因此压缩词项占用的空间就成为了一个必须要解决的问题。
实际上,对于不同类型的数据,实现压缩的方式也是有所不同的,其中包括有:1. 整数压缩 (前缀0不再记录)、2. PackedBlock (本质是固定长度的整形数组的结构 --- 在实际存储中就是Block 【一旦超过128就会变为PackedBlock】)、3. VIntBlock (通过VInt方式压缩整数 【大同小异还是只记录实际有数值的部分】)
数据解析方式
整数压缩
ElasticSearch 通过使用 PackedBlock 和 VIntBlock 针对 .doc 进行解析,每处理 128 个文档就会将其对应的文档ID数组 (docDeltaBuffer) 和词频 (TermFreq) 数组(freqBuffer)处理为两个Block;PackedDocDeltaBlock 和 PackedFreqBlock,并且会将 PackedInts 类对数据进行压缩变为 PackedBlock。如果剩余不足达到 128 那么依旧用 VIntBlock 存储
FOR压缩存储
除了上文的去掉整数压缩方式以外,还可以通过跟 PackedBlock 中长度为128的数组的上一个相差的大小,这样即使数据本身很大也一样可以用很小的大小解决出存储问题。
数据搜索问题
实际上我们的文档往往会有多个字段,在进行查询的时候也往往会通过多个条件的方式来实现查询效果,根据上文提到的es实际存储格式,我们显然可以知道,只要我们的搜索条件是针对多个字段进行的,那么对es来说,搜索要求就会成为:先从所有的field之中找到符合各自条件的结果,然后再对这些结果做交集处理,显然的这样搜索的性能会非常差。
Bitmaps
为了解决这个问题,首先可以考虑的就是位图。**位图(bitmap)**非常熟悉,redis之中一样存在该结构,在解决缓存穿透的时候,有提到过通过Hyperloglog就是基于位图实现的。在es之中,这也是实现交集查询的主要结构。其实就是将不同field的数组的AND结果构造出新的数组结果,并将这个结构成为 bitmaps 。(但是显然的,通过这种方式实现,显然会消耗大量的空间,需要大量的数组来构造出各种需要的 AND 结果、并且bitmap这种AND运算明显只适合简单的数据结构)
显然单纯的bitmap不能直接解决这些问题。因此es实际上使用的是一种压缩过后的bitmaps,叫做 Roaring Bitmaps。
Roaring Bitmaps
本质上roaring bitmaps其实就是针对bitmaps的压缩存储效果。如果没空,不建议看下面的内容,没啥用。
Roaring Bitmaps 每一个都会包含一个 highLowContainer 的 RoaringArray,其中他会将地址拆解为高位部分和低位部分,高位部分组成keys 低位部分则存入到 container之中实现类似于二分查找法的高位定位一块低位部分的效果 (1.8之后hashMap扩容机制跟这个部分有类似的效果)
RoaringArray内部会包含有以下三个结构:1. keys 2.values 3. size
实际存储的时候,会将高 16位 部分拆解到 keys 之中存储,而低 16 位则保存到 values 之中。而key数组和values数组通过下标一一各对应组成一个 32为的数。
通过这个方式就可以实现以类似于二分查找法的方式帮助快速定位目标的container,并且在实际存储的时候,由于前缀的16位整个范围之中大家公共的,所以相当于少用了两个直接记录
Container介绍
Container是RoaringBitmaps,其中主要包括有:
1.ArrayContainer [short 记录一般int的低16位,元素排序后放到short数组之中 最大长度4096,超过4096后自动转变为BitmapContainer] (本质上因为性能问题,这里没有使用bitmaps)
复杂度是 O(logN)2.BitmapContainer [使用long[]记录低16位,数据内容对应long类型的bit位 来记录数据位图结果数据] (真正意义上开始用到bitmap了,但实际上完全就是直接记录bitMaps一般等同于不连续且非常稠密的bitmap结构之中) 但内部结构中的数据降低到4096之下的之后就会回退到ArrayContainer。
复杂度是O(1)3.RunContainer [低16位用short[]记录,将连续出现的数据通过RLE压缩长度算法,将重复出现的数据用一次记录 + 出现次数的方式来记录]。
(当超过4096且可以实现压缩的时候,使用该结构,本身其实跟Bitmaps是一样的,只不过在可压缩时,会转变为这个结构)
跳表结构
跳表这里就不用多介绍了并没有什么特别的,就是在链表的基础上加上了跳转到其他节点的指针索引位置的指针,这样就可以通过跳表的协助实现快速定位。
索引生命周期ILM
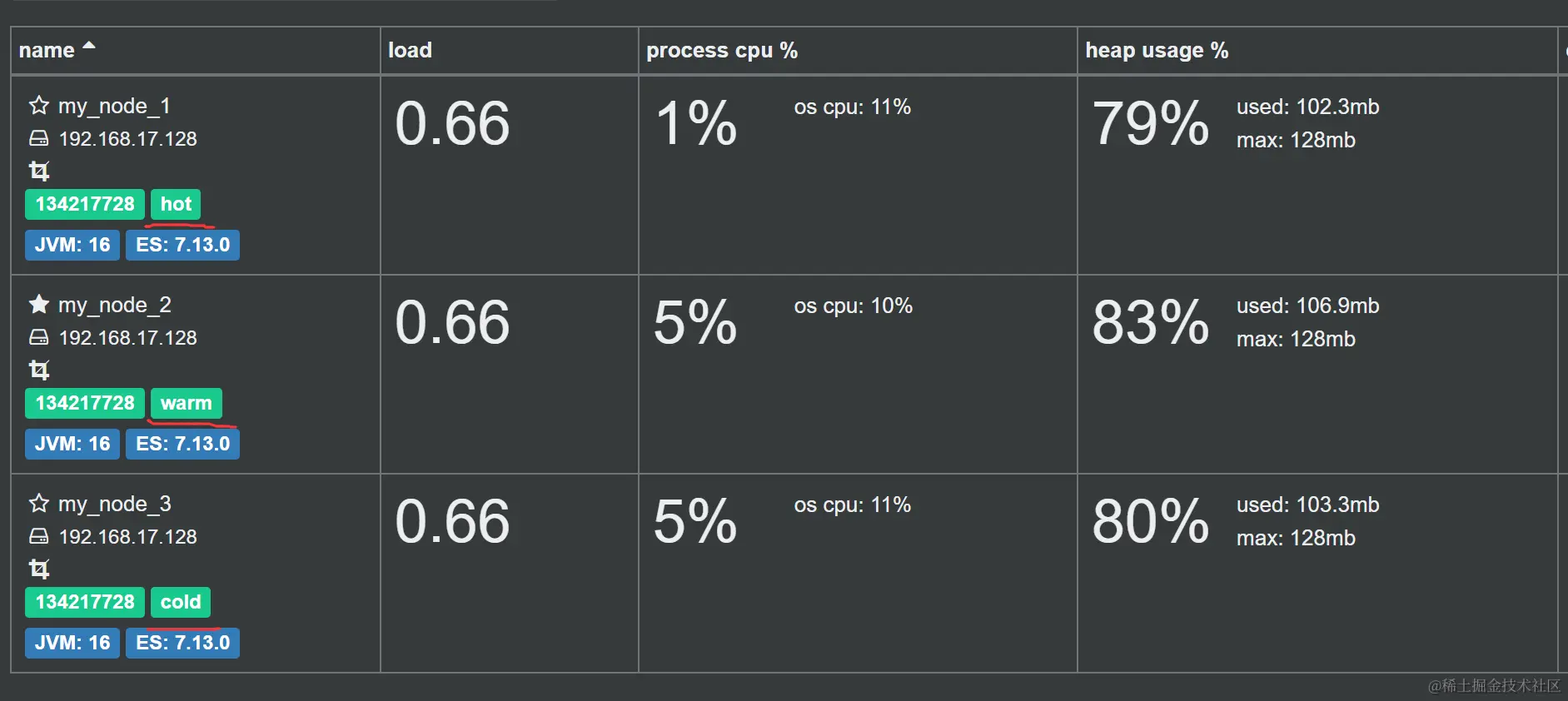
集群节点设置
// 设置 node1 为 hot 节点
node.attr.box_type: hot
// 设置 node2 为 warm 节点
node.attr.box_type: warm
// 设置 node3 为 cold 节点
node.attr.box_type: cold
// 如果是docker-compose启动的集群,可以通过以下配置
environment:
- node.name=my_node1
- node.attr.box_type=hot
environment:
- node.name=my_node2
- node.attr.box_type=warm
environment:
- node.name=my_node3
- node.attr.box_type=cold
索引生命周期 (ILM)
在当前文档之中,对索引构建期间,又或者在索引的行为规定的期间,有一些内容会提到使用ILM_POLICY,在索引的一定时期自动的做某些操作 (自动化的索引管理功能) 。这里补充介绍一下,索引的ILM到底是什么。
阶段 (Phrase)
ES在概念上,将一个索引的生命周期区分为以下多个阶段:
HOT -> Warm -> Cold -> Frozen -> Delete
**HOT:**索引处于 写入、查询的活跃期间,这时一般采用最快的存储设备
**WARM:**索引处于 写入很少、但是查询还比较频繁的情况,一般来说采用性能稍微较差,但是容量很大的存储设备
**COLD:**很少被查询的情况,一般来说,直接采用机械硬盘这种存储量很大,但是性能也相对应差的设备
**DELETE:**索引数据用不上了,一般来说,会将这种级别的索引直接删除
阶段切换
在下文之中会提及我们配置策略,设置阶段的action。实际上并不是我们当索引超过我们配置的某个阶段的min_age就会自动切换到某个阶段,min_age只是其中一个条件,还有一个条件是,前一个阶段的action必须已经触发。
比如说我在hot之中配置了 rollover ,那么只有当 rollover 已经触发了,并且存活的时间超过了 min_age 那么才会进入到下一个阶段。
行为 (Action)
-
Set Priority:设置Index的处理优先级,如果出现节点宕机等情况恢复时,将会依靠该配置项来按照优先级逐个恢复索引 [可用于 Hot / Warm / Cold]
-
Rollover:设置该Action,可以在索引数据发展到某个规模 / 时间点的时候,自动创建切换到新索引继续使用 [可用于Hot] (非常常见于 ELK 记录日志的处理的索引中)
Rollover可以配置项包含以下的内容:
- max_age:最大的创建时间,意思是经过多长的时间后,再次创建新的索引来存储数据。
- max_docs:最大文档树,但文档的总数 (主分片上的文档数量) 达到一个指定值之后触发
- max_size:索引大小,当索引的主分片的大小超过指定的值之后触发
- max_primary_shard_size:主分片大小,但某个主分片的大小超过指定大小之后触发
"max_age": "2d", "max_docs": 1001, "max_size": "20gb", "max_primary_shard_size": "5gb" -
Migrate:自动化的索引迁移,实际上就是将索引的节点组做迁移 [可用于Warm / Cold] (一般用在索引从Hot阶段转移到Warm或者Warm转到Cold等场景下,也比较常见于 ELK 记录日志的处理索引之中)
如果在一个策略之中 配置了 allocate 进行分配选项的话,那么 migrate 操作就会被禁止 -
Searchable Snapshot:自动化的索引生成快照,一般用于生成定时检查的场景等。 [可用于Hot / Cold / Frozen]
-
Wait For Snapshot:在删除索引之前,等待ILM协议执行完毕,一般用于在潜在对数据产生危险影响行为之前的保护工作 [可用于Delete] (删除前提前生成快照、备份等)
-
Allocate:提供自动化的索引设置更新,可以重新分配索引分片的存储节点和更改分片的副本数量等。 [可用于Warm / Cold]
可配置选项有以下四个:【这四个必须指定一个,否则就会报错】
- number_of_replicas:设置副本的数量
- include:优先将分片分配到符合某些条件的节点上
- exclude:拒绝把分片分配到符合某些条件的节点上
- require:必须把分片分配到符合某些条件的节点上
"allocate": { "include": { "box_type": "$[hot, warm, cold]" // 任意组合 hot warm cold }, "$[exclude / require]": { /* same as include */ }, "${number_of_replicas}": n // n 个副本数 } -
Read-Only:设置之后,索引会变为只读状态 [可用于Hot / Warm / Cold]
-
Force Merge:强制合并索引,可以最大限度的减少索引占用的Segment文件的数量 [可用于Hot / Warm] (等同于加强了存储期间的 Merge 行为)
-
Shrink:跟下文的Shrink是一样的,其实就是设置自动化的索引收缩 [可用于Hot / Warm]
底层是通过通过利用 Linux 的硬链接的方式实现的 (这里涉及Linux底层,不多介绍)
-
Freeze:自动化的冻结索引,减少其占用的存储空间 [可用于Cold] (一般用在索引往生命周期后期转变的阶段时,对数据做冷热分离)
- Open:索引可读写,倒排索引等数据会被加载到内存中的缓存,该状态下搜索性能高
- Frozen:索引可读不可写,数据不缓存到内存之中,只占用磁盘空间,搜索性能低
- Close:索引不可读写,不占用内存,只占用磁盘
// 冻结索引 index POST /${index}/_freeze // 解冻索引 POST /${index}/_unfreeze // 查询当前已经冻结的索引 (默认情况下是无法检索到数据的,需要额外参数) POST /${index}/_search?ignore_throttled=false // 使用ignore_throttled 为 false { "query": {"match_all": {}} } -
Delete:自动化删除索引 [可用于Delete]
-
Unfollow:设置该Action之后,可以使得索引本身从异地多机房的官方CCR架构 / 主从状态下的索引 状态下的转变为普通索引,随后我们就可以针对该索引做收缩等会影响索引数据的操作 [可用于Hot / Warm / Cold] (ES禁止主从 / 多机房的修改行为避免级联风暴)
策略 (Policy)
上文提到的阶段和阶段期间可以使用的行为,但是需要注意的是,上文仅仅介绍了在索引的某个阶段可以有什么行为,但是并不能完整的组成一个完整的索引生命周期配置。而如果想要做到针对索引的自动化配置级别的设置,那就需要配置策略。
以下是一个简单的声明策略的模板
// 定义一个策略
PUT _ilm/policy/${policyName}
{
"policy": {
"phases": {
"hot": {
"min_age": "0s", // 触发前一个阶段的action之后
// 最少要度过多少时间才会变为某个阶段
"actions": {
${built-in action}: { /* built-in action struct */ }
},
"set_priority": {
"priority": n // 设置 hot 阶段的索引的优先级
}
},
"warm": { /* same as hot */ },
"cold": { /* same as hot */ },
"delete": { /* same as hot */ }
}
}
}
// 声明一个 hot阶段 大小超过5GB、年龄超过30天 就会创建新索引、且设置 Warm 阶段会将索引副本数量设置为 1
PUT _ilm/policy/my_index
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB",
"max_age": "30d"
}
}
},
"warm": {
"action": {
"migrate": {},
"allocate": {
"number_of_replicas": 1
}
}
}
}
}
}
ILM绑定到索引
// 将 ilm 绑定到 某个索引上,方式1 & 方式2
PUT ${index}
{
"${mappings}": { /* mappings struct */ },
"settings": {
"index.lifecycle.name": "${udf_ilm}"
}
}
PUT ${index}/_settings
{
"settings": {
"index.lifecycle.name": "${udf_ilm}"
}
}
ILM绑定到索引模板
PUT _template/${template_name}
{
/* template struct */
"inedx_patterns": ["${index_prefix}*"],
"settings": {
"index": {
"lifecycle": {
"name": "${udf_ilm_policy}",
"rollover_alias": "${create index alias}"
},
"routing": {
"allocation": {
"$[include/exclude/require]": {
"box_type": "$[hot,warm,clod]"
}
}
}
},
/* other settings struct */
}
}
使用模板创建初始索引
PUT ${inedx_prefix}000001
{
"aliases": {
"${alias_name}": { // 构造相同别名,通过别名可做整体查询 / 写入等操作
"is_write_index": true
}
},
"mappings": {
"properties": { "${field}": { "type": "${field_type}" } }
}
}
通过API管理Policy
我们可以通过请求来查看ILM服务的状态,以及通过请求开启 / 关闭ILM 服务。
// 获取 ILM 状态 返回operation_mode 可能 RUNNING、STOPPING、STOPPED
GET _ilm/status
// 停止 ILM 执行
POST _ilm/stop
// 开启 ILM 服务
POST _ilm/start
ILM Status
- RUNNING:ILM 服务正在执行
- STOPPING:停止ILM服务,但是部分的Action还在执行
- STOPED:彻底停止 ILM 服务
当然我们也可以使用explain 查看一个或者多个索引生命周期指定的 policy 执行的状态
GET ${index}/_ilm/explain
策略执行原理
上面仅介绍了policy的创建,但是没有提到我们的policy关于怎么样执行,实际上在默认的情况下,我们的Policy在后台会经过 10 分钟轮询的方式来执行。
因此现在回头看一下我们phases之中的min_age,实际上他的意思是,变为目前配置的阶段最少需要经过多少时间。假设我们设置是 hot -> warm 最少需要10s的时间,这并不代表索引从hot -> warm只需要经过十秒就行,在最糟糕的情况下,这个过程需要十分钟。
但是一般来说 ILM Policy 的轮询时间不会做进一步的缩减,这是因为本质上降低间隔时间会对集群的压力进一步加大。当然如果非要改可以参考以下的配置
PUT _cluster/settings
{
"persistent": { "indices.lifecycle.poll_interval":"$[ns/nm/nh]" } // 最大24h
}
但 _ilm 策略执行异常的时候,可以使用以下请求重试策略
POST /${index}/_ilm/retry
Kibana中的Policy管理
除了通过API来对 ES 的 ILM Policy 进行管理以外,我们还可以通过使用 Kibana 来实现针对 Policy 的管理。
Stack Management -> Index Lifecycle Policies -> Create policy
右上角可以创建新的 policy ,当然我们也可以直接修改现在已经存在的policy

在policy的编辑页面我们可以指定 phases 的action做配置,全部都可以通过页面配置的方式实现。 (需要注意的是,在Kibana的配置之中,Hot 阶段是必选的)
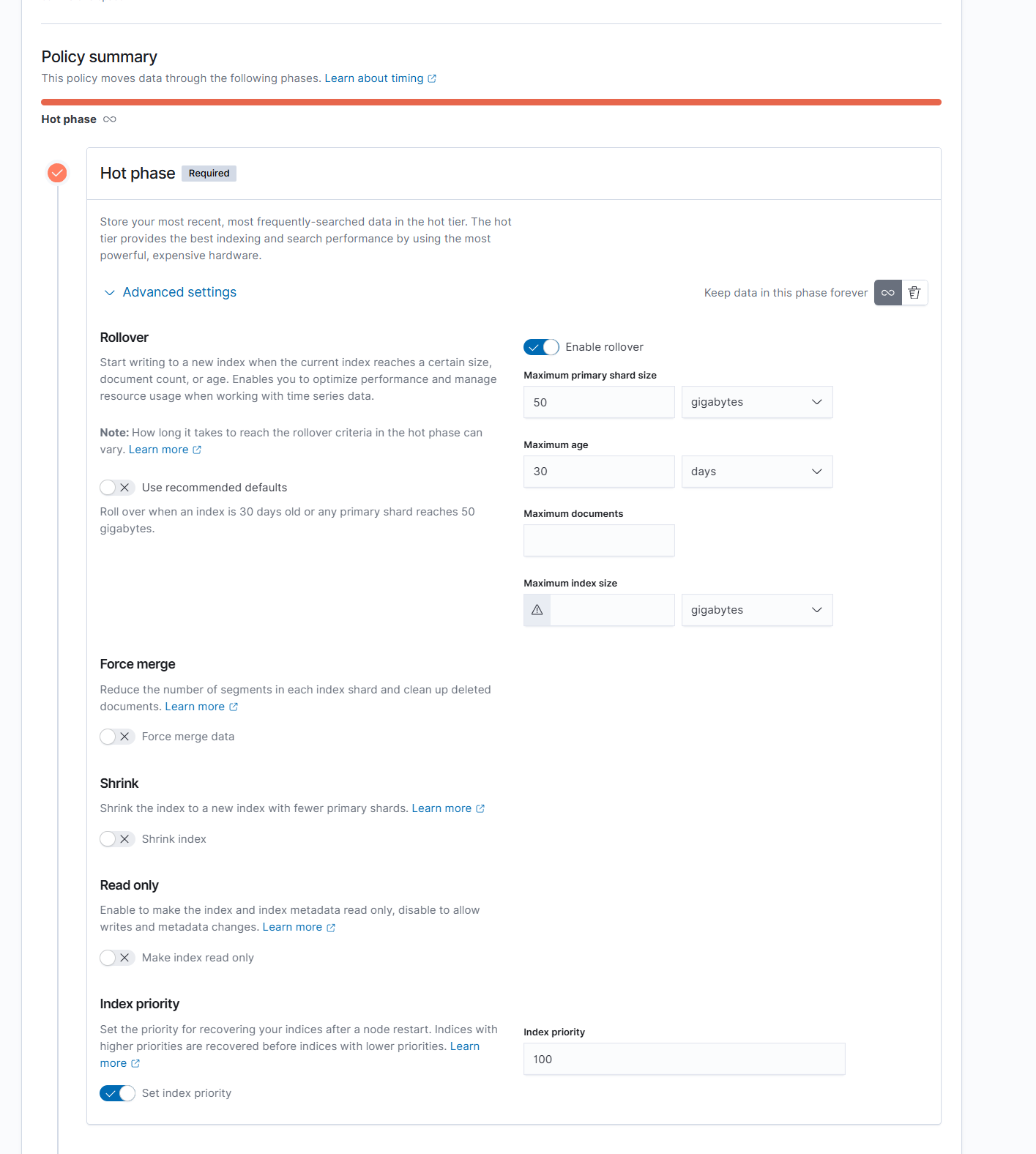
日志ILM示例
鉴于 ElasticSearch 非常常见于日志方面的信息管理,甚至都有出名的ELK框架。并且 ILM 的相关配置也非常常见于日志的使用 (每天分开日志记录等),因此在下面会提供一个简单的日志ILM示例
-
首先,我们按照需要将节点修改为hot warm cold都存在实际的节点的状态
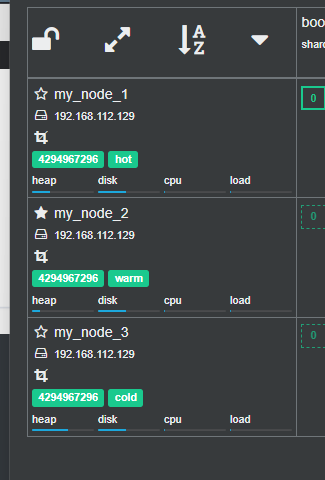
-
通过请求构建一个 ILM 的 policy
PUT /_ilm/policy/log_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_docs": 2 // 超过两个文档触发 action } } }, "warm": { "min_age": "20s", // hot action 触发,并存活超20s转为 warm 节点 "actions": { "allocate": { "include": { "box_type": "warm" } } } }, "cold": { "min_age": "30s", // warm action(若存在) 触发后,存活超30s 转为 cold "actions": { "allocate": { "include": { "box_type": "cold" } } } } } } } -
构建索引模板,并且声明时绑定 ilm_policy
PUT /_template/log_index_template { "index_patterns" : [ "log_index-*" ], "settings" : { "index" : { "lifecycle" : { "name" : "log_policy", "rollover_alias": "app_log" // 索引的别名 }, "routing": { "allocation" : { "include" : { "box_type" : "hot" // 指定被构建的索引会被分配在哪里 } } } }, "number_of_shards" : "1", "number_of_replicas" : "0", "refresh_interval" : "1s" } } -
使用索引模板构建初始索引,并且填充数据两个文档触发 rollover
PUT log_index-000001 { "aliases": { "app_log": { "is_write_index": true } }, "mappings": { "properties": { "log_msg": { "type": "text"} } } } POST app_log/_doc/1 {"log_msg": "不是,哥们v2.0"} POST app_log/_doc/2 {"log_msg": "不是,哥们v2.0"}
最终结果如下所示:
00001索引从Warm转变为Cold的状态
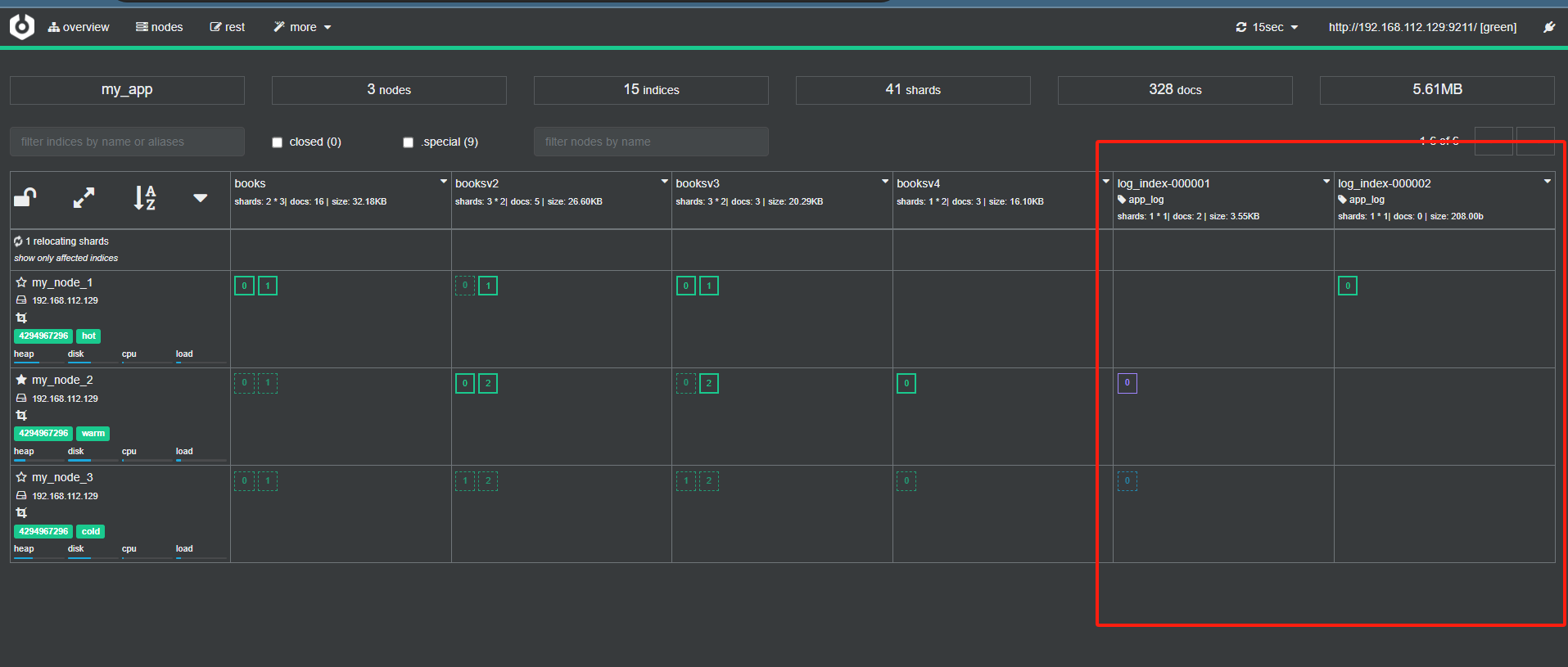
最终状态
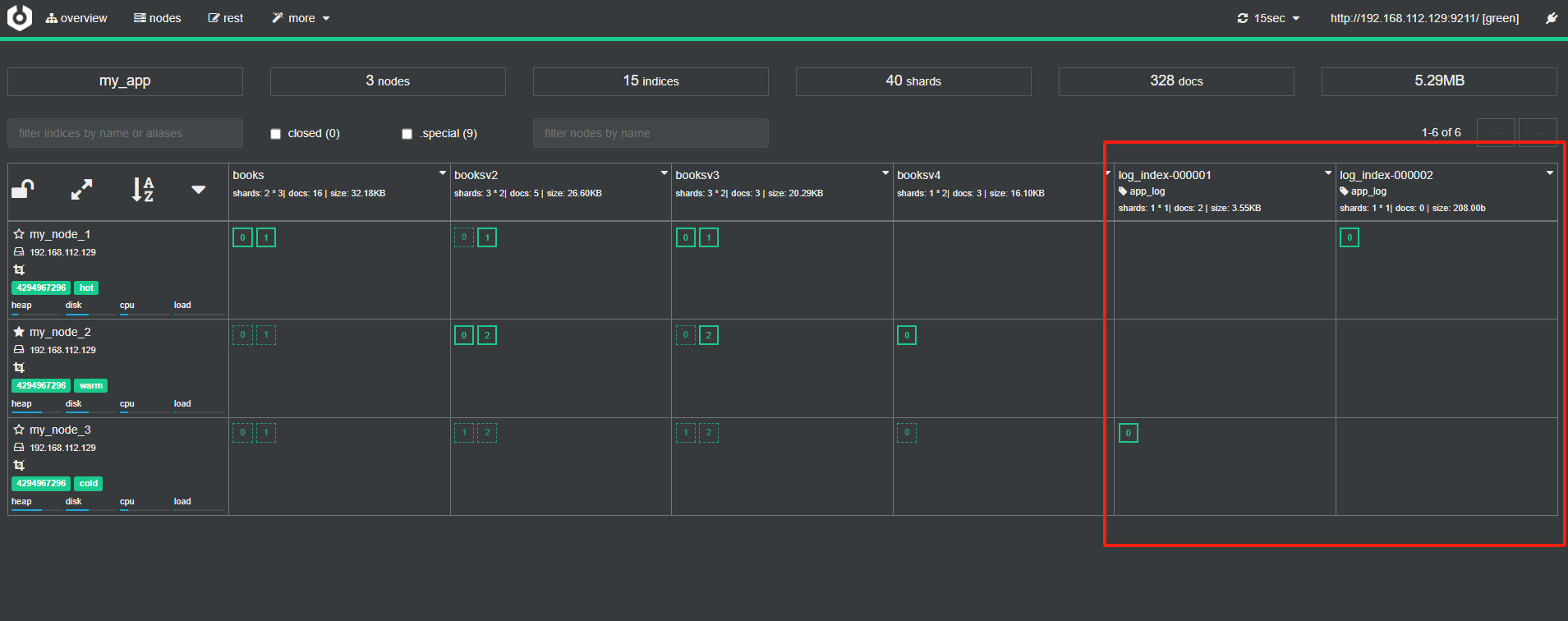 首先,因为文档的数量超过了 policy 在 hot 阶段定义 action中的rollover的max_docs,随后在ilm服务触发之后,es使用索引模板构建了一个新的索引,也就是图中的log_index-000002,并且在log_index-000001存活时间超过20s后,es重新将其分配到了warm节点上,并在超过30s之后又将其分配到了cold节点上,
首先,因为文档的数量超过了 policy 在 hot 阶段定义 action中的rollover的max_docs,随后在ilm服务触发之后,es使用索引模板构建了一个新的索引,也就是图中的log_index-000002,并且在log_index-000001存活时间超过20s后,es重新将其分配到了warm节点上,并在超过30s之后又将其分配到了cold节点上,
此时我们通过使用 GET explain去查看索引的状态的话,可以查看到以下的信息。
GET app_log/_ilm/explain
{
"indices" : {
"log_index-000001" : {
"index" : "log_index-000001",
"managed" : true,
"policy" : "log_policy",
"lifecycle_date_millis" : 1728633309497,
"age" : "8.58m",
"phase" : "cold",
"phase_time_millis" : 1728633339510,
"action" : "complete",
"action_time_millis" : 1728633340183,
"step" : "complete",
"step_time_millis" : 1728633340183,
"phase_execution" : {
"policy" : "log_policy",
"phase_definition" : {
"min_age" : "30s",
"actions" : {
"allocate" : {
"include" : {
"box_type" : "cold"
},
"exclude" : { },
"require" : { }
}
}
},
"version" : 1,
"modified_date_in_millis" : 1728632292690
}
},
"log_index-000002" : {
"index" : "log_index-000002",
"managed" : true,
"policy" : "log_policy",
"lifecycle_date_millis" : 1728633309559,
"age" : "8.58m",
"phase" : "hot",
"phase_time_millis" : 1728633309686,
"action" : "rollover",
"action_time_millis" : 1728633309788,
"step" : "check-rollover-ready",
"step_time_millis" : 1728633309788,
"phase_execution" : {
"policy" : "log_policy",
"phase_definition" : {
"min_age" : "0ms",
"actions" : {
"rollover" : {
"max_docs" : 2
}
}
},
"version" : 1,
"modified_date_in_millis" : 1728632292690
}
}
}
}
当然需要注意的是,如果我们不事先将 ILM 的轮询周期做修改,那么上文这个示例最少也要二十分钟才能测试出来,为了测试方便,可以通过执行以下的命令修改ILM的轮询周期,协助我们做快速的示例
PUT _cluster/settings
{
"persistent": { "indices.lifecycle.poll_interval":"1s" }
}
ES数据存储 / 搜索问题
存储问题
数据压缩
整数压缩
关于整数压缩,上文中对倒排索引的介绍时,已经较为详细的介绍过了,这里不再赘述。
Ordinals压缩
经常处理数据的人都知道,很多的数据或者说文档都需要记录一个字段 status 表明当前的这条数据的状态和使用情况。并且这个字段的大部分的取值都是固定的,在这种情况下,显然的我们的数据本身在存储时候是可以通过某些手段来做优化的。如果我们直接记录,势必会浪费大量的空间。因此 Oridinals 应运而生,我们可以通过解码和压缩的方式降低存储消耗。
简单的Ordinals其实就是通过将某个特定值和普通的整数之间相互替换从而实现压缩的功能。 (keyword -> Integer),这种压缩方式,就被称为 Ordinals 。
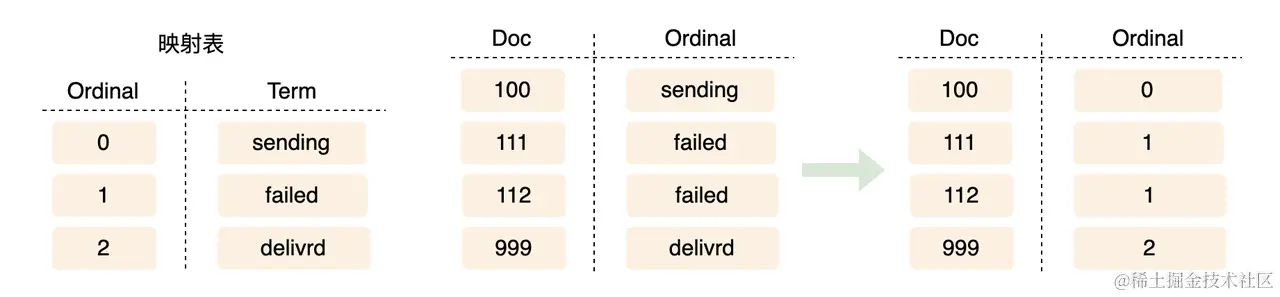
Global Ordinals
上面的Ordinal看起来非常的完美,非常适配我们的需求,但实际上他有个致命的缺点,他只支持单个Segment内部 (被称为 Segment Ordinals Mapping),并不支持分片级别 / 整个集群。而为了实行这样的全局支持,就需要使用 Global Ordinals。也就是 Global Ordinals Mapping。而所谓的Global Ordinals Mappng其实是构建在Segment Ordinals Mapping的。
实际上
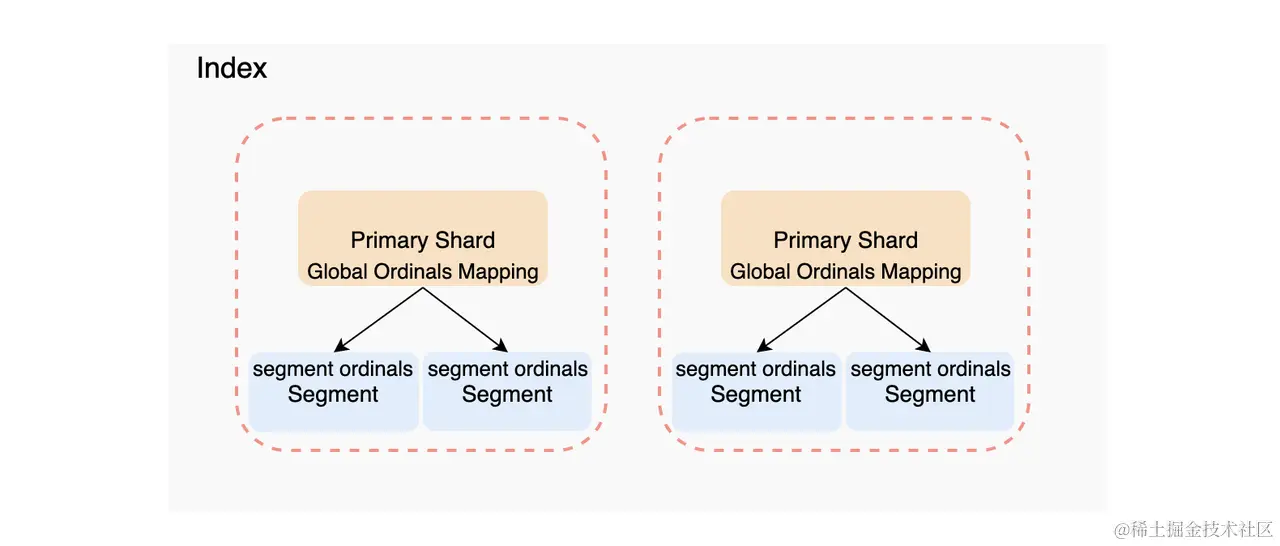
Global Ordinals加载实际,不同于Segment Ordinals的使用,如果想要使用Global Ordinals实现优化,我们需要在构建mapping的时候就针对status一类的keyword类型字段使用 eager_global_ordinals 使其在 shard refreshed 的时候直接做整数对应替换来提高性能。(使 global_ordinals 在数据写入的时候构造出来,而不是在针对 keyword 做聚合的时候才构造,能更有效的提高聚合时的性能)
// 需要注意的是, eager_global_ordinals 必须要在构建mappings的时候就设置好
PUT ${index}/_mapping
{
"properties": {
"${field}": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
什么字段要用Global Ordinals
Ordinals Mapping 只在字符串类型上生效,对于日期、数字类型等无法使用 ,一般来说很常见的会使用Global Ordinals的字段有以下场景:
- 对于 keyword、ip、flattened类型字段进行分桶聚合 (Bucket Affregations) 的时候
- 对于一个打开了 fielddata 的text类型的字段进行分桶聚合的时候,会使用到 Global Ordinals (ES会尝试通过 Global Ordinals 来优化聚合的性能)
- 当我们操作父子操作的时候,对 has_child / parent 聚合的时候。 (嵌套文档在存储之中其实是隐藏文档,将内部的结构映射为整数,能大大提高聚合性能)
配合上上面的信息,我们可以知道 Global Ordinals 往往会使用在:
- Keyword字段 (需要进行聚合的场景)
- 高识别度的字段 (ID / SKU / 邮箱地址等)
- 快速排序的字符串字段
- 开启了 fielddata 的 text字段
- 需要聚合的嵌套对象
- 经常需要聚合的字段
ES数据存储流程
集群角度
实际上不管是插入新的文档还是更新文档,还是删除文档,这些操作本质上都是写入操作。整个流程大致如下:
- 客户端的请求首先到达协调节点,这里假设是Node1,然后Node1默认ed情况下,会将文档的ID或者routing key来进行计算,并得出文档实际应该保存到哪一个分片的结论,并通过内部的分片路由表知道要保存到哪一个分片,就此发起请求告知目标的Node节点。
- Node1将请求转发到目标Node,目标Node将数据存储到 Roaring bitmaps 下,成功完成这个步骤之后,就会将保存请求转发到副本所在的节点,要求副本也做存储操作。(其他节点本身也会有一个节点分片分布路由表)
- 副本所在的节点,受到保存请求之后,就会执行保存工作。并在完成自己的写入操作之后,把自己完成操作的消息发送给最初的协调节点。完成数据的写入工作。
ES数据索引(写入文档)的流程
从单个分片的角度来看,其实整个插入的过程可以更加具体化。
-
客户端将请求发送到es的服务端的时候,具体的节点接收到请求之后,就会将文档之中的field作为 精确值和字符值 拆分出来。
-
es针对精确值和字符值的处理,其实是不一样的
- 精确值直接构建正排索引也就是在elasticsearch入门的介绍之中所提到的构建doc_values协助实现快速的聚合、排序等效果
- 字符值来说,则是将其首先交由char_filter做字符串级别的过滤,一般包含有html标签的处理等;然后再轮到分词器出场,针对内容做分词处理产生大量的词项,最后在通过filter之中指定的过滤器针对分词结果做处理;最后es就可以针对过滤后的词项,做倒排索引的构建。
节点角度
ES的整个数据持久化的流程其实可以被概括为以下流程:(这个部分跟Mysql也是几乎一模一样)
-
Index Buffer 阶段 -- 客户端调用,文档被插入到Index Buffer之中 [数据缓冲池-es服务级别]
(一个 Index Buffer 的大小要稍微小于 一个 Lucene Segement 的大小)
-
Refersh 阶段 (ES缓冲区 -> OS缓冲区) -- 默认的情况下,每当操作发生到大概一秒 / index buffer的大小几乎要被填满,es就会调用Refersh,首先他会将 index buffer 之中的文档存放到 systemfile cache 之中,也就是放到OS的临时缓存文件之中 (作为Lucene的一个Segment) [Refersh机制的存在是为了避免频繁执行 fsync] index.refersh_interval 可以配置refersh的时间间隔
实际上在Refersh的效果还有以下:- 写入的文档可以被搜索到的前提是从Index Buffer之中被刷新过一次
- Index Buffer之中的数据即使没有满,也会被刷新
也可以手动通过命令来执行refersh
# 可以通过手动的方式触发 refersh POST /_refersh POST /${index}/_refersh -
Transaction Log 阶段 (日志备份) -- 为了避免写入的文档,在进入到systemfile cache之后,在某种情况下,如果发生机器宕机等情况,有可能会导致数据丢失,为了避免这个问题,es引入了TransactionLog来记录写入到 ES 之中的文档来避免发生丢失问题。 (需要注意的是,写入到Index Buffer的时候就会同步写入到Transaction Log之中,并且需要注意的是Transaction Log不会随着Index Buffer被Refersh刷新,而是会被 flush 写入到磁盘之中刷新)
总的来说: (相当于用一个较小的日志记录直接写入到磁盘之中,避免丢失问题,但是需要注意的是,使用Transaction Log每一次写入都是直接写入到磁盘中,会造成较小性能影响)
-
**Flush 阶段 ** (磁盘持久化 fsync) -- ES会通过使用 Flush 将位于systemfile cache 之中的文档保存到磁盘之中,本质上其实就是调用系统的 fsync 将操作系统缓存之中的数据刷盘写入到磁盘之中。
一般来说有两种方式,可以触发Flush操作。- 一般来说,ES官方会每30分钟执行一次Flush操作,将 systemfiel cache 写入到磁盘之中
- 跟Index Buffer刷入到systemfile cache类似的,Flush也会因为Transaction Log满了触发Flush
在flush阶段之中,还会产生checkpoint的持久化记录,记录最后一个持久化节点。
-
Merge 阶段 (磁盘融合) -- 上文提到过refersh之中,不管我们的文档处于的Index Buffer是否已经填满,又或者是否是只存了一部分的空间都会将整个Index Buffer的内容作为一个新的 Lucene Segment 的方式进行存储,这样的效果就是会有大量的碎片化的 Lucene Segment,为了避免这个造成大量空间浪费的问题,es通过使用 merge 来对这些 Segment 进行合并,合并完成之后,会将合并的数据删除掉,并且将磁盘之中的删除之后空闲的Segement删掉。
我们也可以通过手动命令的方式来执行合并操作
// 马上进行合并操作 PUT ${index}/_forcemmerge // 配置某个索引的合并参数 PUT ${index}/_settings { "index": { "merge.scheduler.max_thread_count": n, "merge.policy.max_merged_segment": "ngb / nmb" } }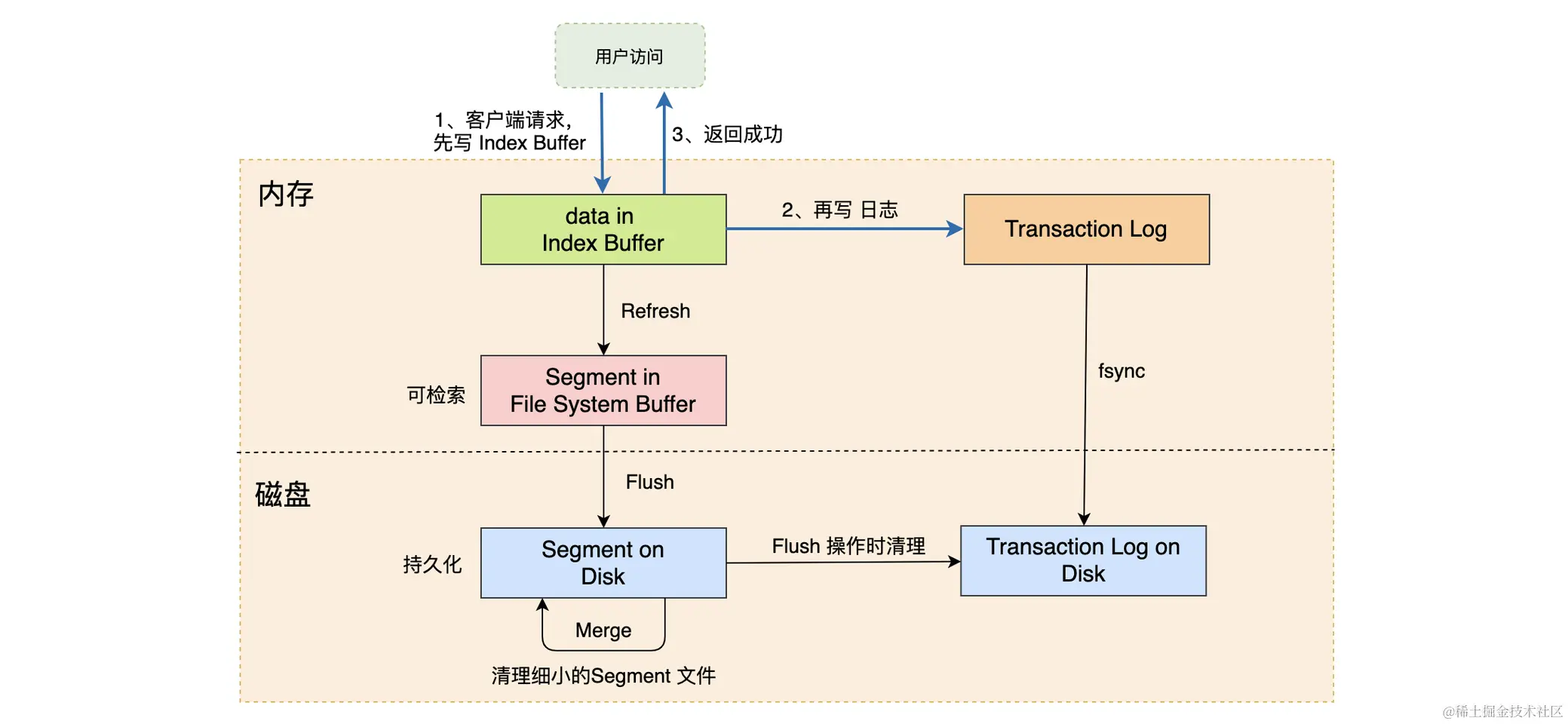
搜索问题
ES数据路由算法
实际上我们的数据会通过一定的算法和逻辑方式映射到某个节点上。一般来说,会有以下的几种映射方式。
随机算法
将数据随机写到某个分片之中,这样做的好处就是逻辑简单、无脑,并且按照hash。但问题在于,后续通过es进行搜索的时候,无法确定数据处于哪一个分片之中,往往会导致我们需要对所有的分片都做搜索出来才行,这样的结果就是搜索起来性能会比较差。
通过Key的值进行映射
实际上该方式才是es进行映射的实际方式,这一点在es的官方文档之中也有相关的介绍:Routing a Document to a Shard | Elasticsearch 。而如果我们在实际使用的时候,如果我们不指定 routing 的值,那么es会默认使用id作为 routing 的值来计算hash,并最终通过以下的函数进行计算,并最终决定记录在哪一个分片之中。而在学习es的时候,我们知道如果我们不指定文档的id,那么实际上和这个的值等同于随机生成的,按照这个值来生成并存储的数据,最终完全等同于上面的随机算法。
shard = hash(routing) % number_of_primary_shards
如果想要控制部分数据的存储那我们必须事先指定文档的routing值,才能保证数据存储到指定的分片之中。
相关性偏差问题
在ES之中实际上每一个shards都是具有自己针对文档做评分计算的,而因为针对数据的评分计算实际上是在具体的每一个Shards自身上进行的,根据之前学习到的TF-IDF计算方式进行计算的时候,因为实际短语和词项的匹配结果完全是依赖于词频 TF 和逆文档频率 IDF 进行统计的。这样就导致某些文档可能由于过于集中在某个分片上,导致有些数据的得分很低。这种情况就被称为相关性偏差问题。
导致相关性偏差的原因可能是多种的:
- 设置routing不合理
- 分片大小差异
如果想要解决相关性偏差的问题,一般来说有三种方式:
-
可以将主分片的数量设置为1,所有数据就将只会交由一个分片进行统计计算
-
使用DFS Query Then Fetch (DFS模式进行搜索)
使用该方式进行查询的时候,数据的评分处理将会从各个shards本身更改为协调节点,从而保证了评分不会出现偏差的问题,但是使用该模式会导致查询的效率大大降低。
GET ${index}/_search?search_type=dfs_query_then_fetch { "query": { "$[term / match]": { term search struct / match search struct } } } -
使用随机分配的原则让文档自定义分配到各个分片上,而不是指定 routing 或者是其他的一些分配方式来决定文档的分配,从而尽量避免数据评分的问题出现 (但是使用随机分配,那就势必会导致数据查询的时候,无法通过指定routing来优化查询性能)
ES的搜索流程
一般来说ES的搜索,可以分为两个角度来看搜索的流程,分别是集群的角度来看搜索的流程:
集群角度
-
Query阶段:查询阶段,主要获取文档的排序值和文档ID到协调节点。并且需要注意的是协调节点通过排序的时候,需要事先确定获取的文档ID的列表。
流程:
- 客户端发起 Search 请求到 Node1。
- 协调节点 Node1 将查询请求转发到索引的每个主分片或者副分片之中,每个分片都会执行本地查询,并且讲查询的结果返回。(并且会将分页查询的 from + size [这里的是from + size 也就是from之前的数据也会被查出来然后返回] (本质上跟innodb的一次获取一个fetchSize大小个结果是类似) 个结果保存到 from + size 大小的有序队列之中)
- 每个分片都会将查询的结果返回到 Node1 的协调节点之中,再对所有的结果进行排序放到全局的排序队列之中,准备再返回
-
Fetch阶段:协调节点从Query阶段产生的全局排序列表之中确定需要使用的文档ID列表,然后通过路由算法计算出各个文档对应的分片,通过使用multi get的方式到对应的分片本身上获取文档。
流程:
- 协调节点 Node1 确定哪些文档需要获取,然后向相关节点发起 multi get 请求;
- 分片所在节点读取文档数据,并且进行 _source 字段进行过滤, 处理高亮参数等,然后把处理的文档数据最终返回给协调节点。
- 协调节点等待所有的数据返回被取回给到客户端
简单来说,其实整个查询分为两个部分,首先es需要协调节点从其他节点身上请求到相同数量的数据,并且将数据相互排序最终存放到一个全局的排序队列之中。然后再根据数量截取全局排序队列的一部分,从其中的ID到对应分片之中找到目标上的。最后再返回给客户端。
节点角度
从搜索的角度来看,整个流程其实又可以具体为以下步骤:
-
请求到达协调节点之后,会对查询的字段做判断,查看是精确值还是全文类型
-
针对精确值和字符串类型会有不同的处理逻辑
- 如果是精确值类型,那么es会将他直接做文档匹配,并将匹配结果返回
- 如果是全文类型,那么es首先会对全文类型的查询内容,通过字符串过滤(index声明时编写的char_filter) -> 通过分词对字符串进行分词处理(index声明时编写的analyzer) -> 通过过滤器对分词的词项结果进行过滤处理(index声明时编写的filter) -> 对分词过滤结果做文档匹配,在倒排索引之中进行匹配搜索 -> 根据相关性进行排序结果处理